关于虚拟机内存和JVM内存设置的思考
背景
最近有同事总问JVM的设置问题.
之前总结过不少. 但是感觉没法讲对方说服
当然了, 自己能力有限, 只能自说自话.
现在这个就是留存一个底稿. 希望能人能帮忙解释
关于内存和CPU的观点
CPU的能力有上限. 一般情况下不建议让CPU处于高峰作业.
尤其是 x86 的机器 有超线程, 其实CPU显示使用率超过一半的CPU时就已经快到上限了.所以机器的性能 40%左右的CPU 可能相应时间和吞吐量都比较好一些.
超过 50% 超线程中的 另外一个线程开始争抢寄存器, 性能就会下降. 但是CPU使用率有非常依赖内存的使用情况.
内存高, 不需要swap,不需要gc, 不需要线程切换换入换出. CPU的压力就小
会主要进行 业务操作的CPU. 但是如果机器内存不专一, 会导致 sys cpu升高
如果JVM设置的不合理, 经常fullgc 会倒是 user cpu升高.CPU性能好的机器 可以容忍, 但是如果CPU性能不好,尤其是访存和内存带宽不高的机器.
此时就会导致非常严重的性能问题.所以提升性能的本质, 就是减少内存的非主观操作, 减少FullGC,减少内存被动的换入换出.
关于信创的思考
现在国家队信创的要求主要在于CPU
磁盘和内存可以选用非国产的设备.因为国产化是一个持久化的过程,现阶段来看,
国产CPU的性能距离Intel最新的CPU还有5-8年的差距.此时扬长避短就是一个很必要的措施.
增加内存, 减少CPU的工作, 避免swap,换入换出,fullGC
通过减少CPU的压力来提高响应效率和增加吞吐量.高速的CPU,高速的内存能够减少内存latch,lock以及数据库的lock
的持有时间, 能够减少lock wait, 减少死锁出现的概率
提高产品执行效率, 降低响应时间. 提高客户体验. 国产化的虚拟机系统可能会增加一些安全审计相关的组件. 会都占用部分内存
虚拟机的内存要至少大于 jvm的堆区 10G 左右才比较安全. 因为根据之前的经验. 系统会占用 1-2G的内存.
非堆区占用 4G 左右的内存
因为读写文件会占用buffer和cache, 也会占用2G左右的内存.
还要空余一部分内存应对突发的响应. 如果内存不足,导致使用到了swap, 性能会指数级的下降.
所以最开始的K8S 都要求关闭swap, 出现内存不够, 立即OOM
通过fast failure 的方式来避免 应用卡顿, 产生不可控的事件.
一个现象
公司里面一堆机器在跑自动化.
其中有一台机器的FullGC特别高
发现 这个机器的 xmx的设置不合理,跟其他机器不一样.稍微大一点的内存能够极大的减少fullGC的次数.
内存配置与运行情况
宿主机的监控情况为:
PID USER VIRT RES SHR S %CPU %MEM TIME+ COMMAND
8422 root 19.5g 14.1g 144680 S 771.5 29.8 2843:18 javajvm的内存配置为: 10G
-XX:InitialHeapSize=10737418240 -XX:MaxHeapSize=10737418240然后发现jvm在疯狂GC
图示
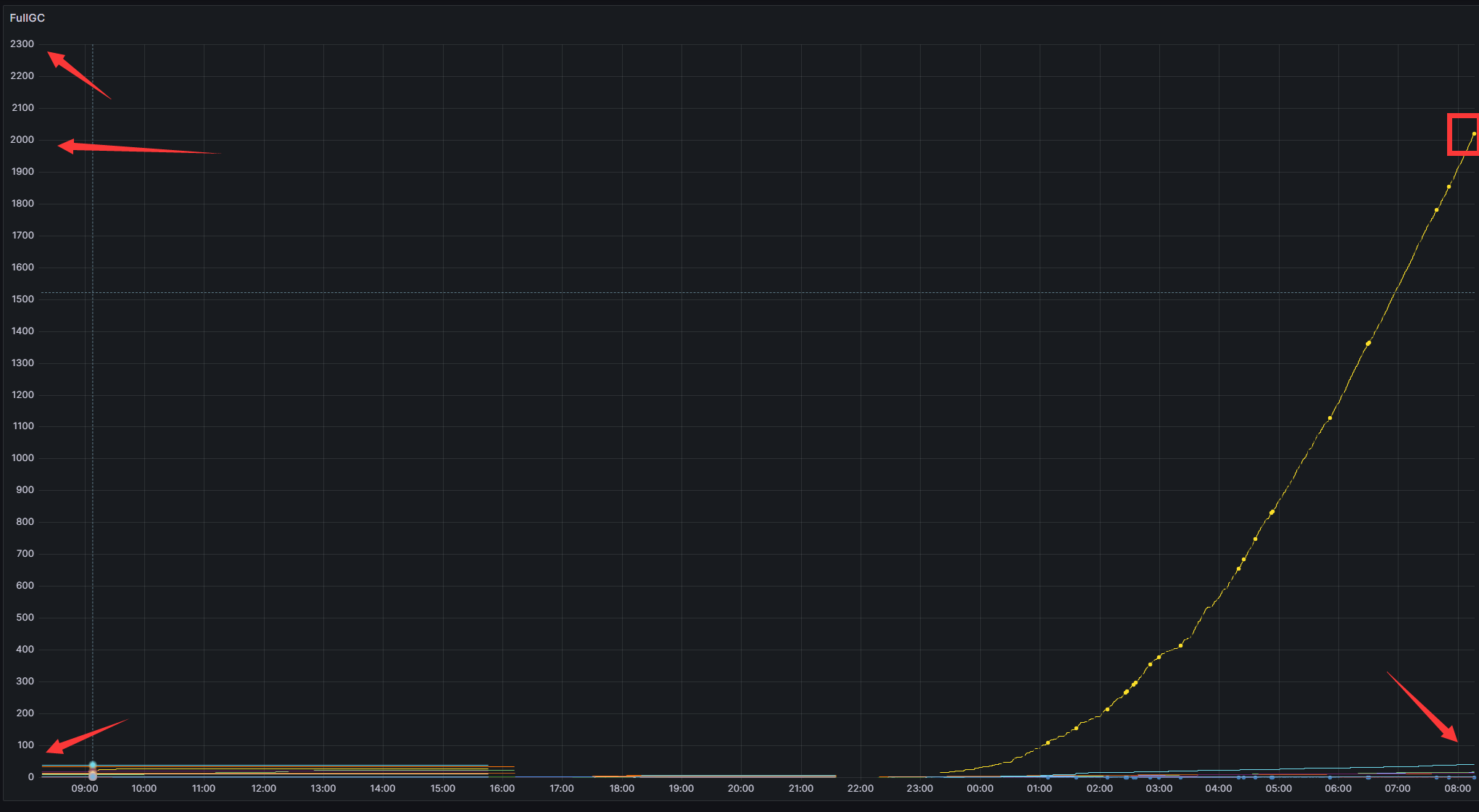
说明
图中很明显可以看到 除了这一个之外, 其他额FullGC次数非常少.这么多fullGC 跟内存大小不太足有很大的关系.
dump分析
time jmap -dump:live,format=b,file=/20240412.hprof 8422
内存使用情况

内存使用分析
最多的几个内存区域
org.springframework.aop.aspectj.annotation.AnnotationAwareAspectJAutoProxyCreator
org.springframework.data.jpa.mapping.JpaMetamodelMappingContext
org.hibernate.metamodel.internal.MetamodelImpl
org.hibernate.service.internal.SessionFactoryServiceRegistryImpl这些基本上占用了接近2G的内存空间. 理论上这些应该都是必须的
剩下 5G的空间是业务代码逻辑使用
所以就太小了.

关于内存占用的分析
堆区设置 10G
top显示内存 14.1G多与的 4.1G 是非堆区. 比较关键的数据应该是包含:
1. 线程栈区
2. 元数据区(包含方法区,也就是类的元数据)
3. 直接内存
4. 本地内存
5. gc,jit等c语言编写的工具使用的内存区域.一般情况下 top 使用的内存减去 xms=xmx=堆区 内存的情况
就应该是比较准确的非堆区整体用量.
内存不足时CPU使用增加
整个java使用的时间为:
2-05:11:50
合计为: 3200分钟左右计算如下的 FullGC的总时间为: 2000分钟
换句话说, FullGC/ALL 时间的比率为: 63%
所以机器其实一直在疯狂的出工, 但是出的力就比较少. PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND8453 root 20 0 19.1g 14.0g 144712 S 0.0 29.7 253:24.53 java8454 root 20 0 19.1g 14.0g 144712 S 0.0 29.7 253:11.33 java8451 root 20 0 19.1g 14.0g 144712 S 0.0 29.7 253:05.68 java8455 root 20 0 19.1g 14.0g 144712 S 0.0 29.7 253:01.91 java8452 root 20 0 19.1g 14.0g 144712 S 0.0 29.7 252:55.15 java8449 root 20 0 19.1g 14.0g 144712 S 0.0 29.7 252:54.04 java8450 root 20 0 19.1g 14.0g 144712 S 0.0 29.7 252:53.27 java8448 root 20 0 19.1g 14.0g 144712 S 0.0 29.7 252:52.40 java相同的一个设置为 24G堆区的机器CPU总时间为:
root 23429 23412 99 4月11 ? 1-05:09:28
1750 分钟左右.查看fullGC相关的时间 累计才 20分钟. 这样的话 大部分业务时间就对应的上了.
23450 root 20 0 35.5g 30.1g 24332 S 0.0 63.8 2:18.84 java
23451 root 20 0 35.5g 30.1g 24332 S 0.0 63.8 2:18.81 java
23452 root 20 0 35.5g 30.1g 24332 S 0.0 63.8 2:18.97 java
23453 root 20 0 35.5g 30.1g 24332 S 0.0 63.8 2:19.43 java
23454 root 20 0 35.5g 30.1g 24332 S 0.0 63.8 2:17.78 java
23455 root 20 0 35.5g 30.1g 24332 S 0.0 63.8 2:18.71 java
23456 root 20 0 35.5g 30.1g 24332 S 0.0 63.8 2:19.03 java
23457 root 20 0 35.5g 30.1g 24332 S 0.0 63.8 2:18.52 java
结论
相同的CPU在不同内存配置的情况下使用的CPU时间有一倍的差距
其中差异的大部分都被因为堆区不太够导致的fullGC消耗的时间来产生.
所以增加堆区, 到一小时不超过一次FullGC的场景下.
机器的性能会比较好一些. 业务高峰期应该建议不要有fullGC的不然会导致卡顿.
如果业务量比较大的FullGC可能至少会产生 10秒-30秒的等待
会导致客户体验明显下降.