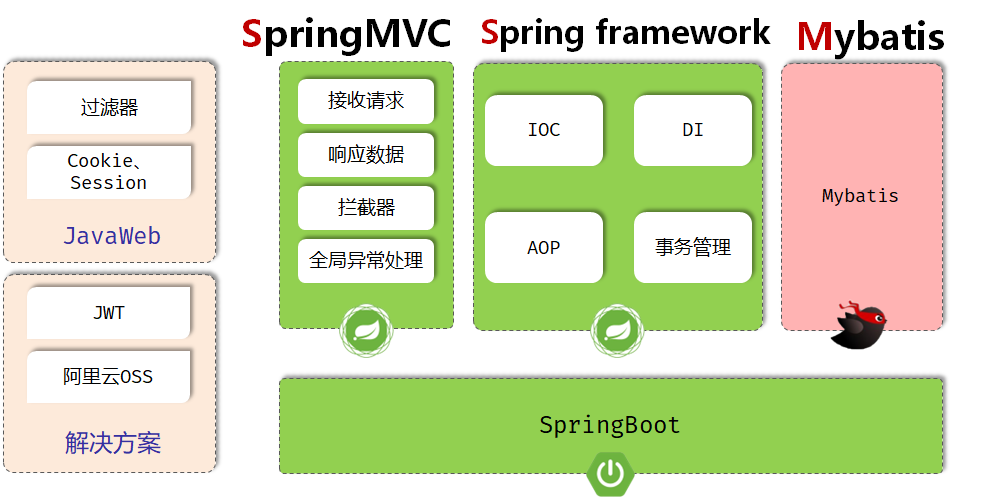
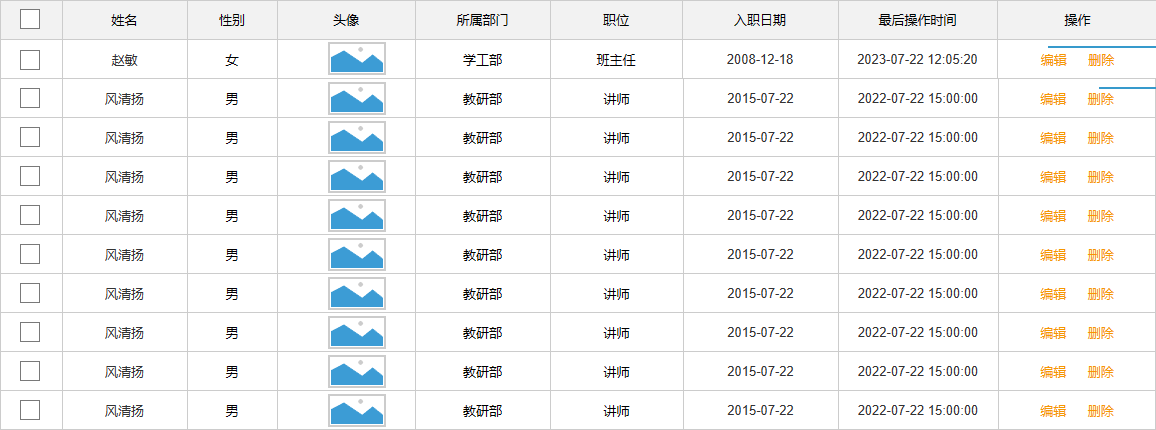
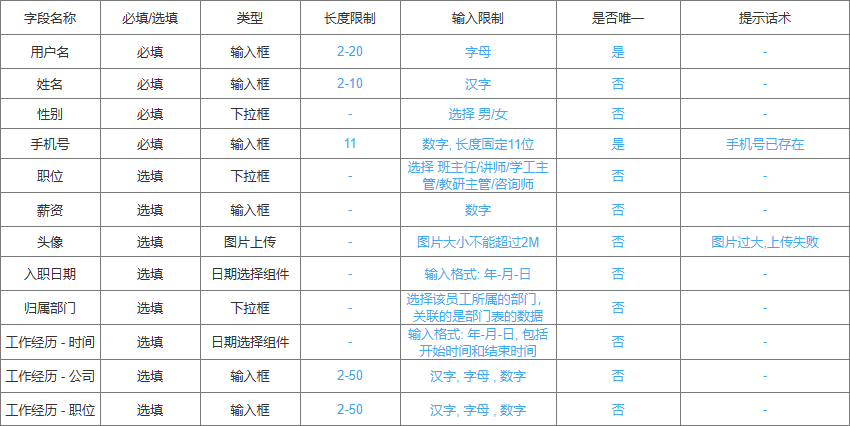
开发规范
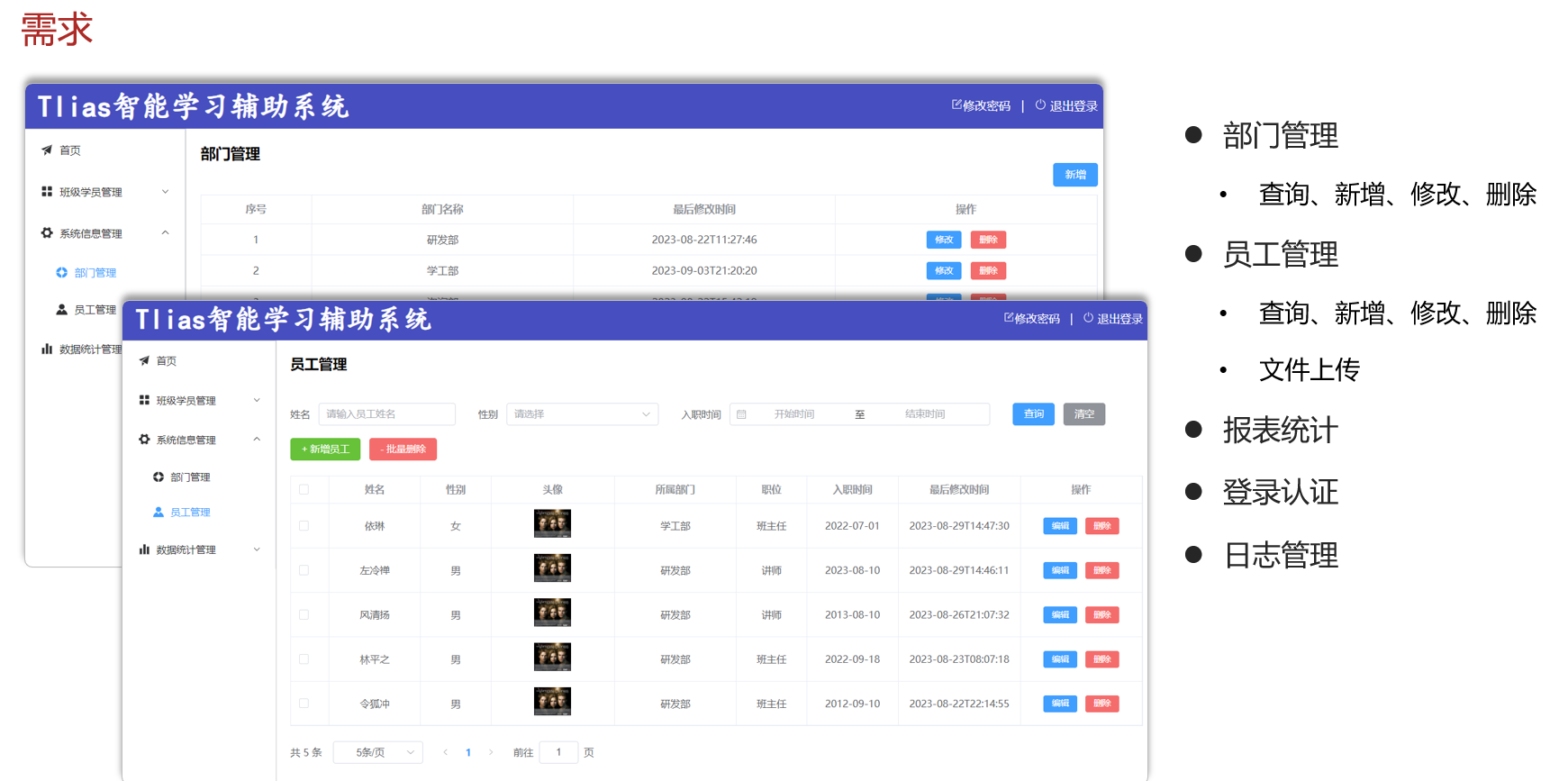
前后端混合开发
- 沟通成本高
- 分工不明确:前端发起请求、数据响应的渲染一般都是后端程序员完成的
- 不便管理
- 难以维护
前后端分离开发
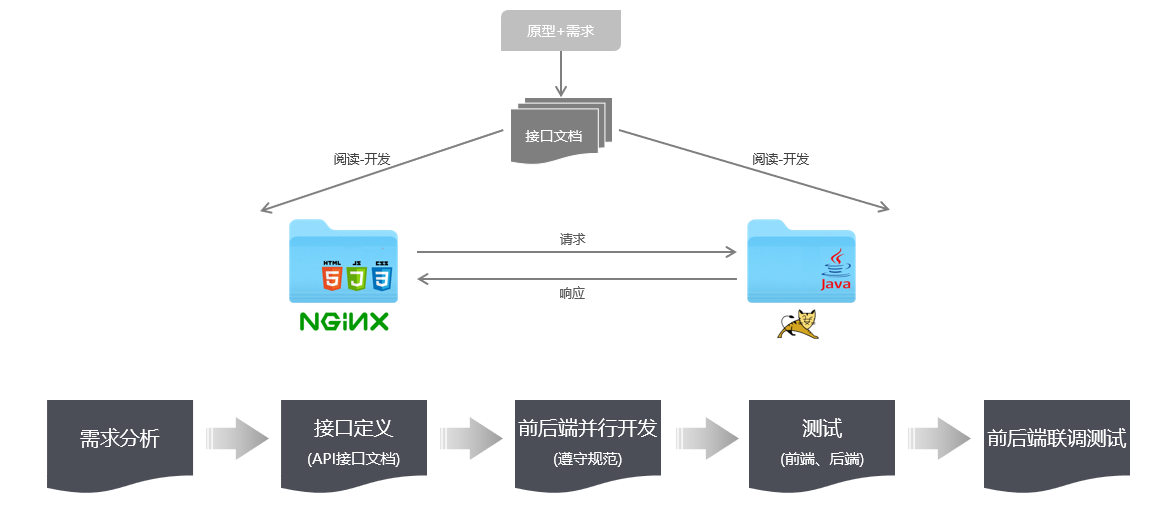
产品经理提供界面原型 + 需求,前端/后端分析并设计出接口文档,有了接口文档前端后端就可以并行开发了
接口文档中的接口是功能性接口,按照功能划分接口
RESTful
REST(REpresentational State Transfer),表述性状态转换,它是一种软件架构风格。

前端向后端发起的请求是RESTful风格的
原先的接口风格:
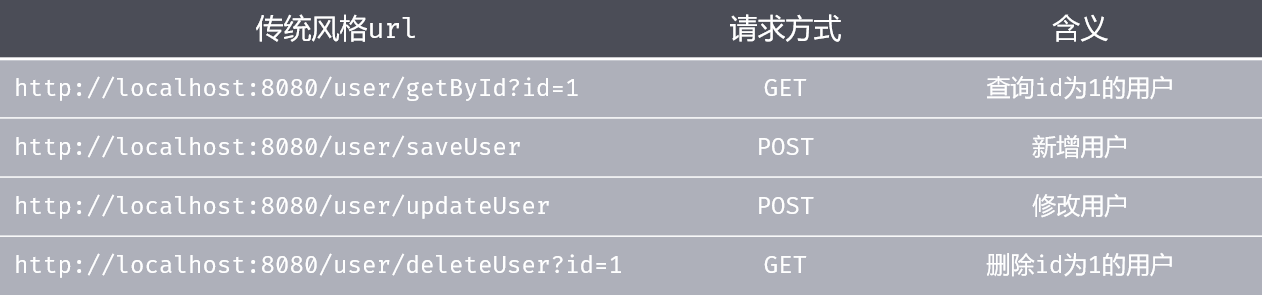
这种风格的缺点是:不规范,难以维护。
因为不同人的开发风格是不同的,比如删除用户不同程序员的命名可能是deleteUser、removeUser等,这样在做大型项目时每一个模块的命名都是不同的,这样不利于后期维护和扩展。
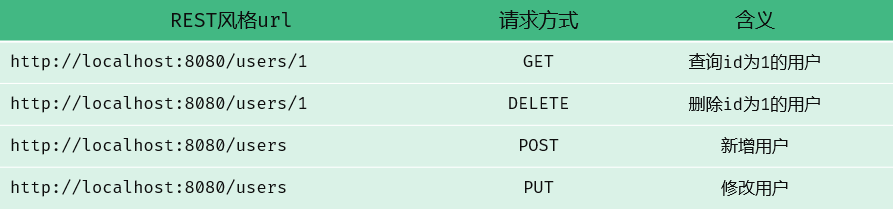
RESTful的特点:
- **URL定位资源
- HTTP动词描述动作
注意:
- RESTful是风格,是约定,但约定并不是规定,约定是可以打破的
- 描述功能模块通常使用复数形式(加s),表示此类资源而非单个资源,比如users
环境搭建
- 前后端并行开发,后端开发完功能后如何对后端接口进行测试呢?
- 前后端并行开发,前端开发时如何获取数据渲染页面呢?
可以使用API fox
Api fox是集成了Api文档、Api调试、Api Mock、Api测试的一体化协作平台
作用:接口文档管理、接口请求测试、Mock服务
查询部门
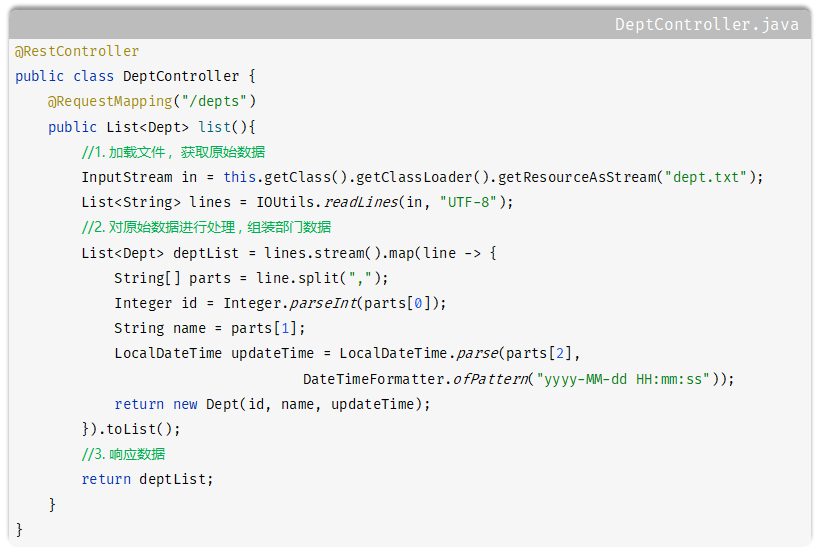
@RestController 是@Controller + @ResponseBofy
当前代码有两个问题:
- RequestMapping未指定请求方式,可以接收所有请求
- 返回结果不统一
- 解决所有请求,让当前方法只接收GET请求
@RequestMapping("",method=GET) //麻烦
@GetMapping("")
- 解决返回结果不统一

应该无论执行哪种增删改查操作,都返回一个同一的结果:
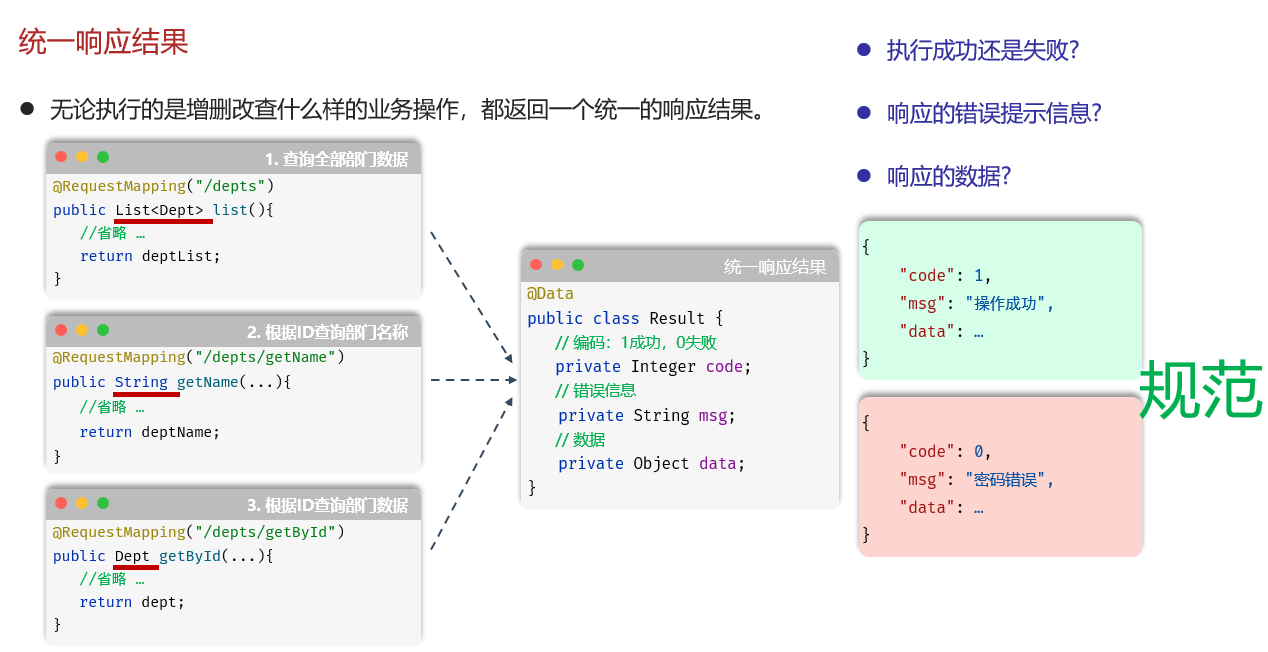
可能出现的问题
如果后端的接口测试没有问题,而前端渲染不到数据,就是前端或后端有一方没有根据接口文档开发,检查接口文档
Nginx反向代理
前端请求的地址为http://localhost:90/api/depts,如何访问到后端的http://localhost:8080/depts呢?
其实是使用了Nginx服务器的[[03-Nginx#Nginx的反向代理|反向代理机制]]
Nginx反向代理:
- 安全
- 灵活
- 负载均衡
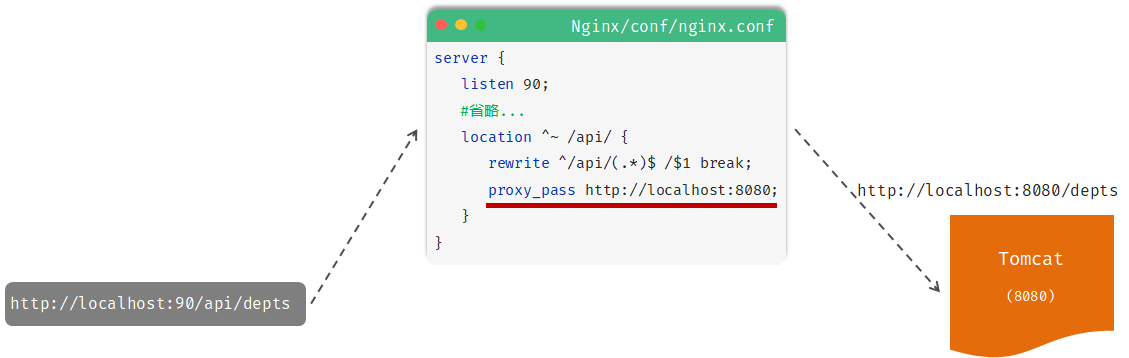
服务器监听90端口的请求,以http://localhost:90/api/depts为例
- location:用于定义匹配特定URL请求的规则
localtion : ^~ /api/ :精确匹配以/api/开头的请求路径,匹配到了/api/depts这个请求
- rewrite:重写匹配到的请求路径
rewrite : ^/api/(.*)$ /$1 break; :精确匹配从/api/到结束的字符串,将该字符串的/api/之后的内容视为一个分组,捕获该分组并重写为/(.*),本例中捕获的分组是depts,重写后的路径是/depts
- proxy_pass:该指令用于代理转发,将匹配到的请求转发给位于后端的指令服务器
proxy_pass : http://localhost:8080 ,此时完整的请求就是 http://localhost:8080/depts

三层架构
见[[Spring#分层解耦|分层解耦]]
项目表结构的设计
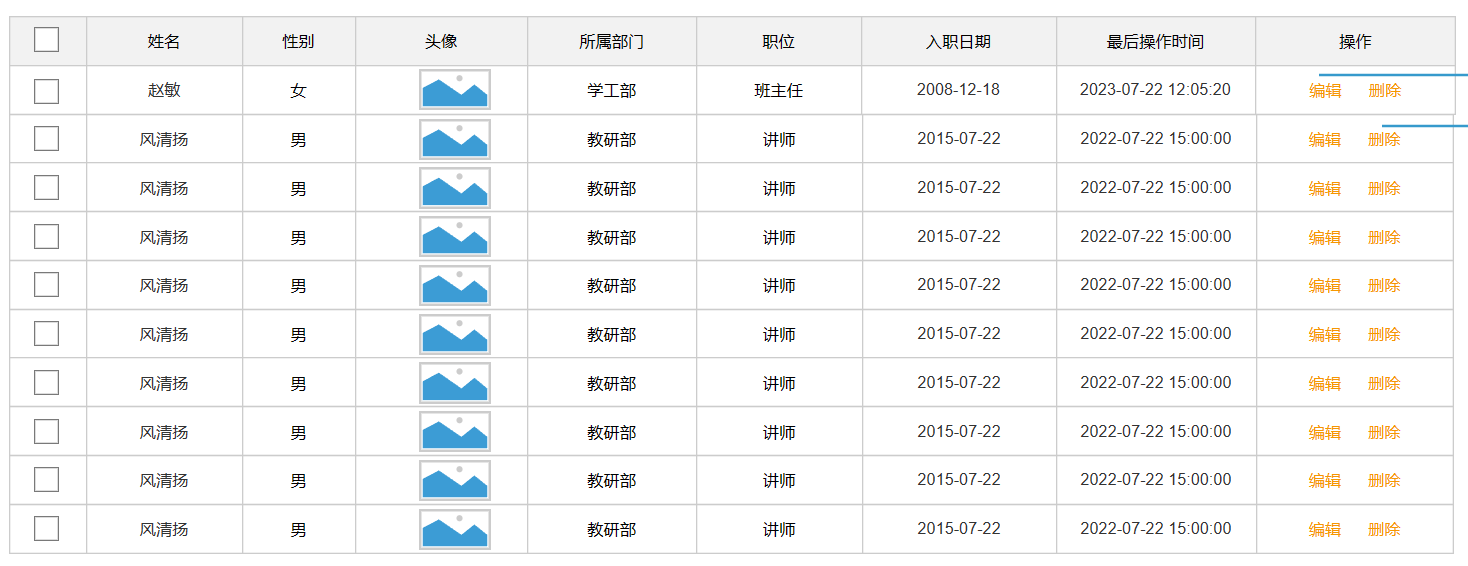
User表
依据界面原型和需求文档设计员工表的结构
界面原型:
需求文档:

create database if not exists itheima02;
use itheima02;
drop table if exists user;
create table user( id int unsigned primary key auto_increment comment 'id 主键 自增', username varchar(20) not null unique comment '用户名', password varchar(50) not null default '123456' comment '密码', name varchar(10) not null unique comment '姓名', gender tinyint unsigned not null comment '1 男 2 女', phone char(11) not null unique comment '手机号', job tinyint unsigned comment '1 讲师 ....', salary int unsigned comment '薪资', image varchar(300) comment '头像图片地址', entry_date date comment '入职日期', create_time datetime comment '创建时间', update_time datetime comment '最后更新时间'
) comment '用户表';
- 根据表格分析出大部分数据,根据需求文档2.5描述添加password字段
- 注意:
- 一般不直接存储 '男' 或 '女',不同的业务场景下展现的可能是 男性 或 男士,应该进行抽象
Dept表
-- 部门管理
create table dept( id int unsigned primary key auto_increment comment '主键ID', name varchar(10) not null unique comment '部门名称', create_time datetime comment '创建时间', update_time datetime comment '修改时间'
) comment '部门表';
- 对于数据库存储的表,一般都会添加三个字段:id、create_time、update_time。id用来标识唯一记录
在原先SpringBoot项目的基础上集成MyBatis:
<dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>3.0.3</version></dependency><dependency> <groupId>com.mysql</groupId> <artifactId>mysql-connector-j</artifactId> <scope>runtime</scope></dependency>
Emp表
注意:其中部门和员工是一对多的关系,将部门主键加入员工表中
create table emp( id int unsigned primary key auto_increment comment 'ID,主键', username varchar(20) not null unique comment '用户名', password varchar(50) default '123456' comment '密码', name varchar(10) not null comment '姓名', gender tinyint unsigned not null comment '性别, 1:男, 2:女', phone char(11) not null unique comment '手机号', job tinyint unsigned comment '职位, 1 班主任, 2 讲师 , 3 学工主管, 4 教研主管, 5 咨询师', salary int unsigned comment '薪资', image varchar(300) comment '头像', entry_date date comment '入职日期', dept_id int unsigned comment '部门ID', create_time datetime comment '创建时间', update_time datetime comment '修改时间'
) comment '员工表';
其中dept_id是逻辑外键。
添加员工:
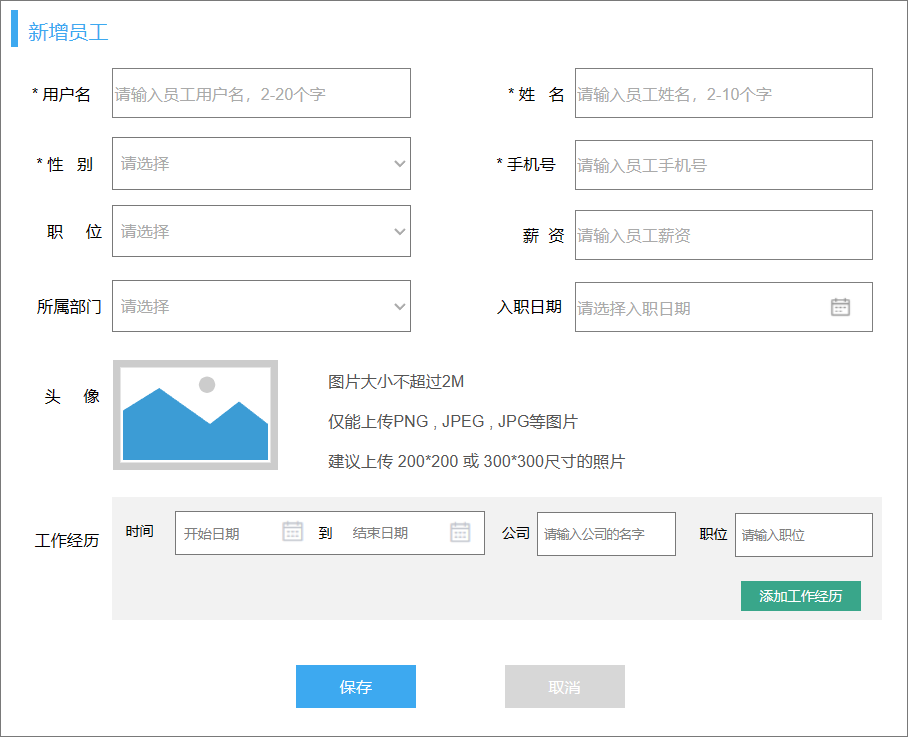
其中员工可能有多段工作经历,员工表和工作经历表是一对多的关系,应该将一方主键加入多方表
create table emp_expr( id int unsigned primary key auto_increment comment '经历id', begin date comment '开始时间', end date comment '结束时间', company varchar(50) comment '公司', job varchar(50) comment '职位', emp_id int unsigned not null comment '员工ID'
) comment '工作经历表';
外键的数据类型要和主键保持一致,此表没有updateTime和createTime,因为工作经历表实际上是员工表的附属表,不会单独的修改工作经历和创建工作经历,实际上是修改员工信息和创建员工信息,修改时间和创建时间也就包含在员工表中了
部门的增删改查
查询部门
@Select("select * from dept")
List<Dept> selectAll();
但需要解决MySQL的snake命名和Java的Camel-Case转换
- Results - Result
- as 起别名
- 自动结果映射
需要注意的是,数据库中存储的是datetime类型的字段,从查询结果集ResultSet获得到的是Timestamp,MyBatis是将Timestamp转化为了LocalDateTime
删除部门
点击删除后,删除数据库中对应的记录。
RESTful风格:前端发起DELETE请求,携带要删除的Dept id DELETE /depts/1
Controller:
@DeleteMapping("/depts/{id}")
public Result deleteREST(@PathVariable("id") Integer id){ Integer i = deptService.removeById(id); if (Integer.valueOf(1).equals(i)){ return Result.success(); }else { return Result.error("删除失败"); } }
需要使用@PathVariable获取路径参数
@RequestParam获取的是请求参数,? 之后的就是请求参数
如果请求路径是:/depts?id=1,就需要使用@RequestParam进行接收:
@DeleteMapping("/depts")
public Result delete(@RequestParam Integer id){ Integer i = deptService.removeById(id); if (Integer.valueOf(1).equals(i)){ return Result.success(); }else { return Result.error("删除失败"); }
}
如果形参和请求的key不同,需要在注解中指定名称。
@RequestParam中有require属性,要求被注解参数必须提供值,默认为true。或者可以指定defaultValue
Service。
Mapper:
需要根据id删除,SQL是: delete from dept where id = #{id}
此处的id就是Mapper接口中方法的参数:
public interface DeptMapper{@Delete("delete from dept where id = #{id}") Integer deleteById(Integer id);
}
如果SQL只有一个参数,方法也只需要一个入参,那么方法的入参可以随便命名(不建议)
如果SQL有多个参数,方法就需要多个入参,那么方法的入参名字就要和占位符中的名字保持一致。
新增部门
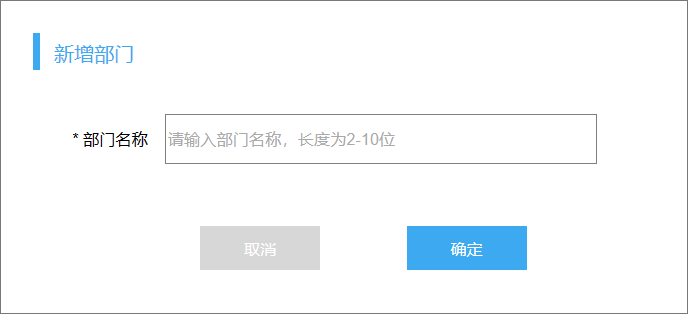
新增部门需要提供部门名称,在前端封装为JSON格式:
{"name" : "教研部"
}
前端发起的POST请求需要设置content-type:json
Controller需要接收JSON格式的数据,就要使用@RequestBody注解
@PostMapping("/depts")
public Result addDept(@RequestBody Dept dept){ deptService.addDept(dept); return Result.success();
}
需要保证JSON的key和Dept类的属性名是一致的。
数据库中dept表有四个字段:
create table dept
( id int unsigned auto_increment comment '主键ID' primary key, name varchar(10) not null comment '部门名称', create_time datetime null comment '创建时间', update_time datetime null comment '修改时间', constraint name unique (name)
)
其中的主键ID为null,create_time、update_time需要我们自己设置。
Service:设置两个时间字段
Mapper:插入数据
@Insert("insert into dept(name, create_time, update_time) values (#{name},#{createTime},#{updateTime})")
void insertDept(Dept dept);
如果content-type是表单,这里就不需要使用@RequestBody了
修改部门
修改部门分为两步:
- 数据回显:发起GET请求根据ID查询部门
- 修改数据:发起PUT请求根据ID修改部门
数据回显
Controller:GET请求携带ID参数
@GetMapping("/depts/{id}")
public Result queryDeptById(@PathVariable Integer id){ return Result.success(deptService.queryDeptById(id));
}
Service
Mapper:
@Select("select * from dept where id = #{id}")
Dept selectById(Integer id);
修改数据
Controller:PUT请求,携带application/json
@PutMapping("/depts")
public Result updateById(@RequestBody Dept dept){ return Result.success(deptService.updateDeptNameById(dept));
}
Service:封装修改时间
@Override
public Integer updateDeptNameById(Dept dept) { dept.setUpdateTime(LocalDateTime.now()); return deptMapper.updateDept(dept);
}
Mapper:update from ...
<update id="updateDept"> update dept <set> <if test="name != null and name != ''"> name = #{name},</if> <if test="updateTime != null"> update_time = #{updateTime},</if> </set> where id = #{id};
</update>
结构优化
类标注@RequestMapping("depts")
Emp的增删改查
前置操作:需要先访问DeptController {/depts} 得到所有的部门信息,为下拉列表准备值。
查
设计Emp pojo:
@Data
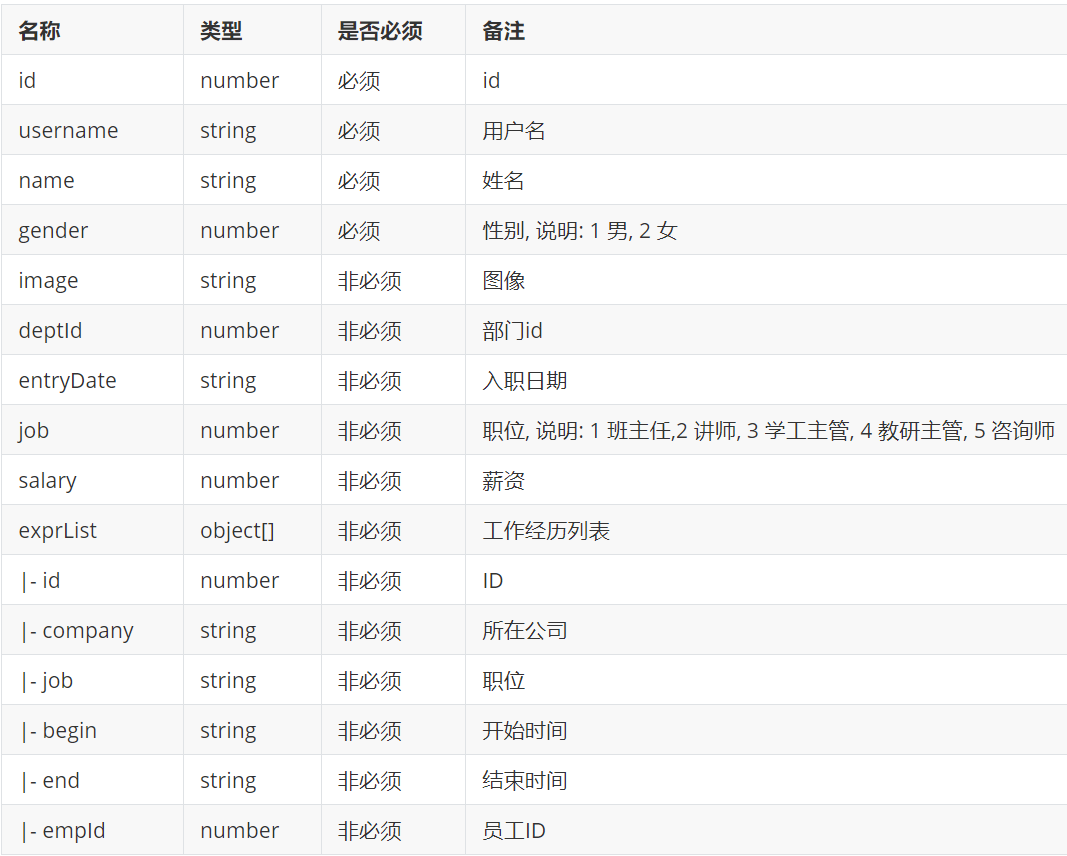
public class Emp { private Integer id; //ID,主键 private String username; //用户名 private String password; //密码 private String name; //姓名 private Integer gender; //性别, 1:男, 2:女 private String phone; //手机号 private Integer job; //职位, 1:班主任,2:讲师,3:学工主管,4:教研主管,5:咨询师 private Integer salary; //薪资 private String image; //头像 private LocalDate entryDate; //入职日期 private LocalDateTime createTime; //创建时间 private LocalDateTime updateTime; //修改时间 private Integer deptId; //关联的部门ID //封装部门名称数 private String deptName; //部门名称 //private Dept dept;
}
设计为单独的字段就不必使用resultMap进行结果映射了
分页查询数据
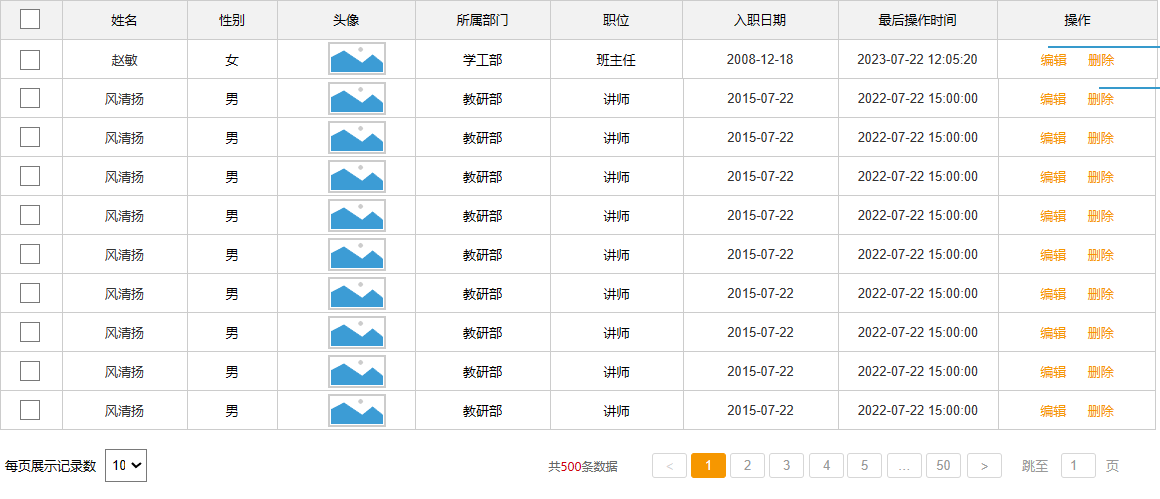
需要显示:
- 分页查询到的记录
- 总记录条数
对应两条SQL语句
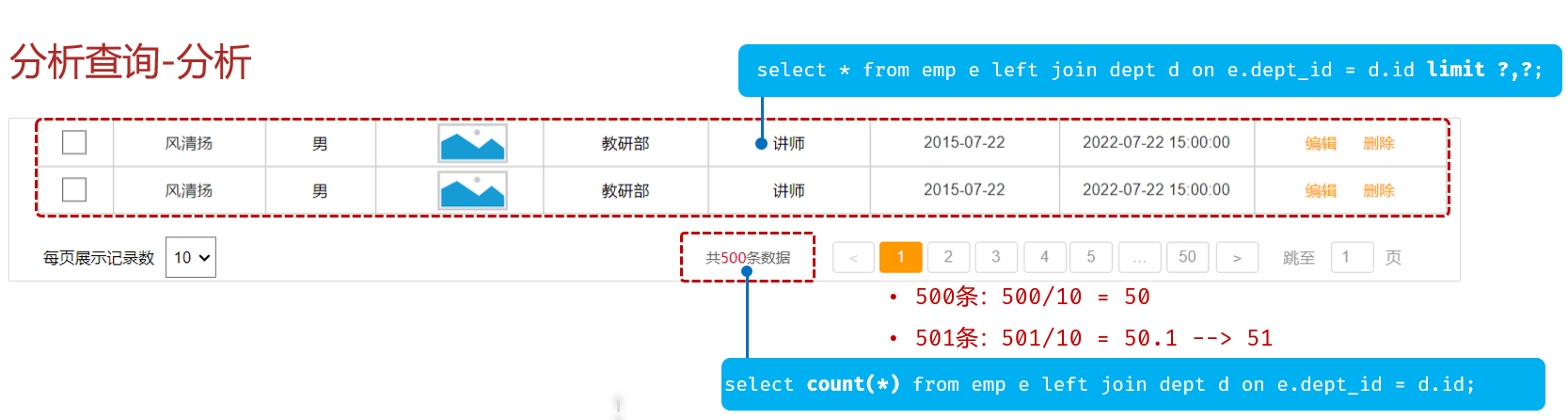
前后端的数据传输:

在接口文档中指定了前端传递的参数格式:
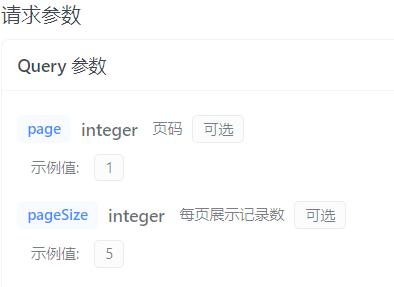
注意,page和pageSize都是可选的,需要我们指定默认值
和后端响应的数据格式:

根据接口文档data字段分析出需要一个PageBean存储分页查询结果的返回值:
@Data
@NoArgsConstructor
@AllArgsConstructor
public class PageBean { private Long total; private List rows;
}
执行流程:

Controller:接收pageNo、pageSize,指定默认值,返回Result
@RestController
@RequestMapping("/emps")
public class EmpController { @Autowired private EmpService empService; @GetMapping public Result pageQuery(@RequestParam(value = "page",defaultValue = "1") Integer pageNo, @RequestParam(defaultValue = "10") Integer pageSize){ PageBean pageBean = empService.pageQueryEmps(pageNo, pageSize); return Result.success(pageBean); }
}
Service:计算beginIndex,获取total、rows,封装pageBean
@Service
public class EmpServiceImpl implements EmpService { @Autowired private EmpMapper empMapper; @Override public PageBean pageQueryEmps(Integer pageNo, Integer pageSize) { Integer beginIndex = (pageNo - 1) * pageSize; PageBean pageBean = new PageBean(); pageBean.setTotal(empMapper.selectTotalCount()); pageBean.setRows(empMapper.selectByPage(beginIndex,pageSize)); return pageBean; }
}
Mapper:查询总记录条数和分页对应数据
@Mapper
public interface EmpMapper { @Select("select emp.*,dept.name deptName from emp join dept on emp.dept_id = dept.id limit #{beginIndex},#{pageSize}") List<Emp> selectByPage(Integer beginIndex, Integer pageSize); @Select("select count(*) from emp join dept on emp.dept_id = dept.id") Long selectTotalCount();
}
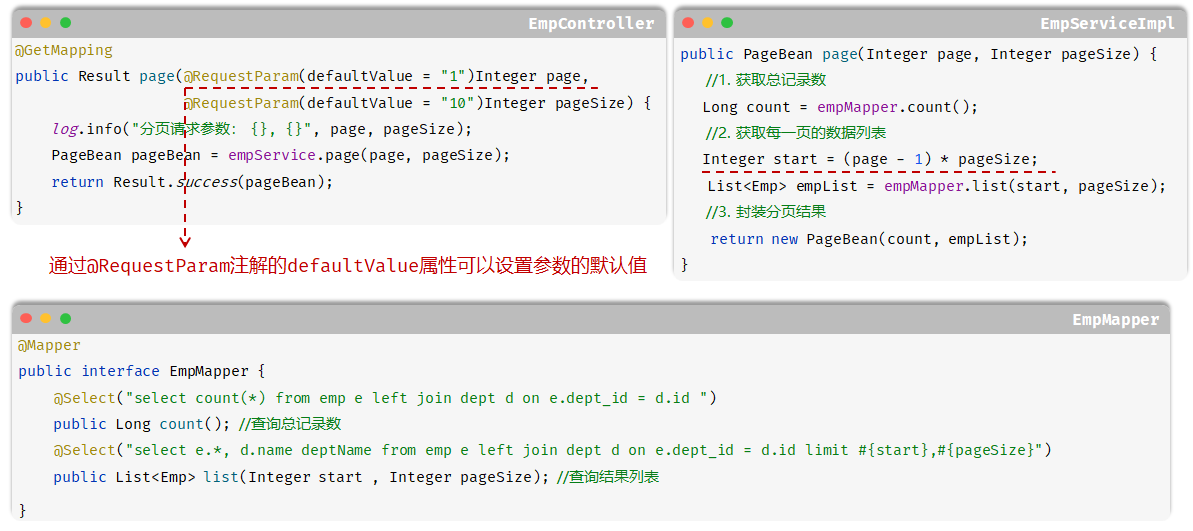
使用pageHelper改善分页查询
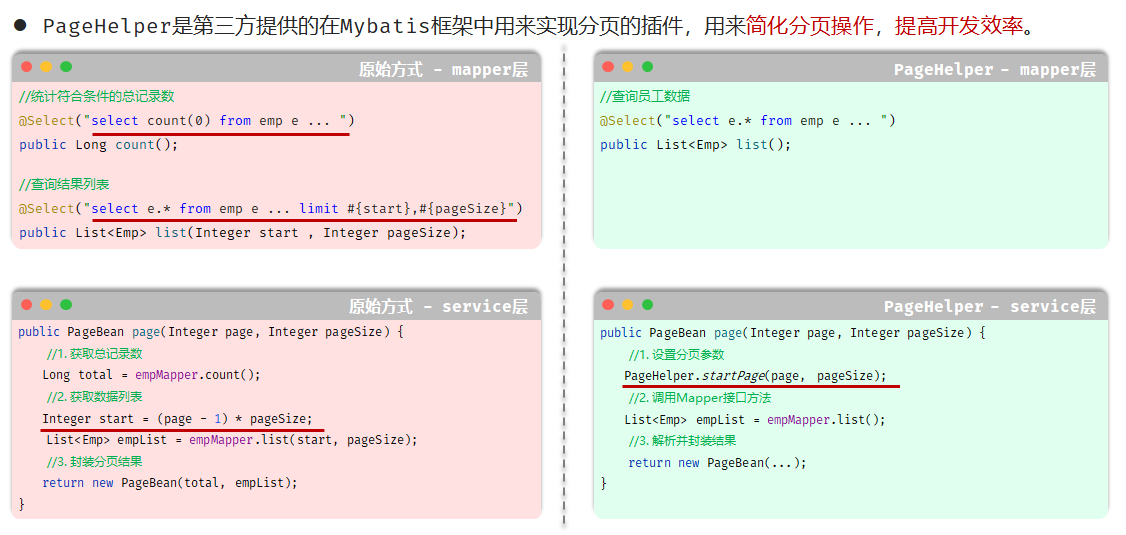
可以发现:
- 分页查询都需要查询总记录条数,也就是都需要写两条SQL语句
- 分页查询都需要根据页码查询起始索引
使用PageHelper可以简化这个过程。
使用步骤:
- 引入PageHelper的依赖
<dependency><groupId>com.github.pagehelper</groupId><artifactId>pagehelper-spring-boot-starter</artifactId><version>1.4.7</version>
</dependency>
- 定义Mapper接口的查询方法(无需考虑分页)
//查询员工数据,无需考虑分页
@Select("select emp.*,d.name deptName from emp join dept d on emp.dept_id = d.id")
List<Emp> selectByPageHelper();
- 在Service方法中实现分页查询
@Override
public PageBean pageQueryEmps(Integer pageNo, Integer pageSize) { PageHelper.startPage(pageNo,pageSize); List<Emp> pages = empMapper.selectByPageHelper(); Page<Emp> emps = (Page<Emp>) pages; return new PageBean(emps.getTotal(),emps.getResult());
}
可能需要的配置文件:
# pageHelper分页配置
pagehelper:helper-dialect: mysqlreasonable: truesupport-methods-arguments: true开启分页后,查询语句得到的结果其实是List<>的子类Page<>,在该类中封装了分页查询相关的信息。
上文所说的分页查询必定会执行两个SQL语句:
- 查询总记录条数
- 查询分页对应的数据
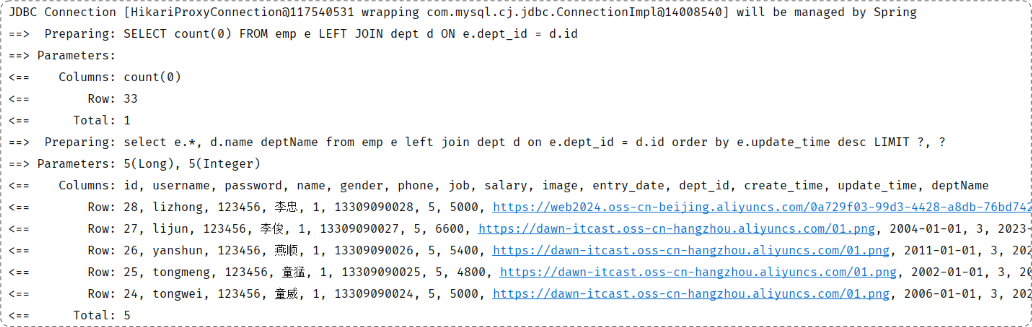
实际上是PageHelper对Mapper中未进行分页的SQL进行了增强。
PageHelper的实现机制:

注意:
- Mapper的SQL语句结尾不要加 ; ,否则拼接limit时会报错
- PageHelper只会对紧跟在其后的第一条SQL语句进行处理
条件分页查询
分页查询已经实现了,现在需要传递条件查询的条件

根据接口文档和正常分析可知,传递的这些参数是可选的,对应后端就是动态的SQL。
界面原型:
之前根据此界面原型设计了基本表的结构
后端查询的要求:

在Controller中接收URL参数,接收的形式:
- 多个入参接收参数
@GetMapping
public Result page(@RequestParam(defaultValue = "1") Integer page, @RequestParam(defaultValue = "2") Integer pageSize,String name, Integer gender,@DateTimeFormat(pattern = "yyyy-MM-dd") LocalDate begin,@DateTimeFormat(pattern = "yyyy-MM-dd") LocalDate end) { log.info("查询请求参数: {}, {}, {}, {}, {}, {}", page, pageSize, name, gender, begin, end);return Result.success();
}但是参数个数较多时不易维护。
- 多个入参封装为查询对象
@Data
public class EmpQueryParam { private Integer page = 1; private Integer pageSize = 10; private String name; private Integer gender; @DateTimeFormat(pattern = "yyyy-MM-dd") private LocalDate begin; @DateTimeFormat(pattern = "yyyy-MM-dd") private LocalDate end; }
对分页参数指定的默认值可以使用显示初始化。
Controller:
@GetMapping
public Result pageQuery(EmpQueryParam empQueryParam){ PageBean pageBean = empService.pageQueryEmps(empQueryParam); return Result.success(pageBean);
}
Service:开启分页
@Override
public PageBean pageQueryEmps(EmpQueryParam empQueryParam) { PageHelper.startPage(empQueryParam.getPage(), empQueryParam.getPageSize()); Page<Emp> emps = (Page<Emp>) empMapper.selectByPageHelper(empQueryParam); return new PageBean(emps.getTotal(),emps.getResult());
}
Mapper:
<select id="selectByPageHelper" resultType="com.itheima.model.pojo.Emp"> select e.*,d.name deptName from emp e join dept d on e.dept_id = d.id <where> <if test="name != null and name != '' ">e.name like concat('%',#{name},'%')</if> <if test="gender != null">and gender = #{gender}</if> <if test="begin != null and end != null">and entry_date between #{begin} and #{end}</if> </where> order by e.update_time desc</select>
注意界面原型要求的排序
增
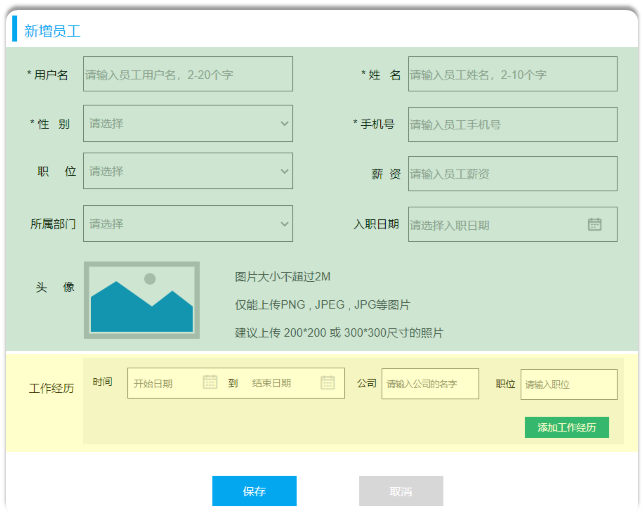
每名员工可能有多份工作经历,工作经历应该定义为一张单独的表。在多方中维护一方的引用
create table emp_expr
( id int unsigned auto_increment comment 'ID, 主键' primary key, emp_id int unsigned null comment '员工ID', begin date null comment '开始时间', end date null comment '结束时间', company varchar(50) null comment '公司名称', job varchar(50) null comment '职位'
) comment '工作经历';对应在Java代码中,就是在Emp中维护一个List<EmpExpr>的引用。
@Data
public class Emp { private Integer id; //ID,主键 private String username; //用户名 private String password; //密码 private String name; //姓名 private Integer gender; //性别, 1:男, 2:女 private String phone; //手机号 private Integer job; //职位, 1:班主任,2:讲师,3:学工主管,4:教研主管,5:咨询师 private Integer salary; //薪资 private String image; //头像 private LocalDate entryDate; //入职日期 @DateTimeFormat(pattern = "yyyy-MM-dd") private LocalDateTime createTime; //创建时间 @DateTimeFormat(pattern = "yyyy-MM-dd") private LocalDateTime updateTime; //修改时间 private Integer deptId; //关联的部门ID //封装部门名称数 private String deptName; //部门名称 //private Dept dept; private List<EmpExpr> exprList;
}
@Data
public class EmpExpr { private Integer id; //ID private Integer empId; //员工ID @DateTimeFormat(pattern = "yyyy-MM-dd") private LocalDate begin; //开始时间 @DateTimeFormat(pattern = "yyyy-MM-dd") private LocalDate end; //结束时间 private String company; //公司名称 private String job; //职位
}
工作经历表没有create_time、update_time,因为工作经历表是作为员工表的附属表,不会单独的为员工添加一个工作经历,如果要为员工添加工作经历实际上就是修改员工信息,只需要在员工表中记录create_time和update_time即可。
Controller层:接收Emp类型的参数
@PostMapping
public Result addEmp(@RequestBody Emp emp) throws Exception { empService.addEmp(emp); return Result.success();
}
Service层:
- 员工信息插入员工表
- 工作经历信息插入工作经历表
@Transactional
@Override
public void addEmp(Emp emp) throws Exception { //1. 添加员工到Emp表 emp.setCreateTime(LocalDateTime.now()); emp.setUpdateTime(LocalDateTime.now()); empMapper.insertEmp(emp); log.info(String.valueOf(emp)); //2. 添加工作经历 // CollectionUtils.isEmpty:为null或为空返回true List<EmpExpr> exprList = emp.getExprList(); if (!CollectionUtils.isEmpty(exprList)) { exprList.forEach(expr -> expr.setEmpId(emp.getId())); empMapper.insertBatch(exprList); }
}
注意:插入员工表后员工的主键id是自增的,第二步插入工作经历需要使用这个自增的id,也就是插入工作经历时需要使用第一步插入员工数据后自增的id。
获取自增的id并封装在指定的字段中:
@Options(useGeneratedKeys = true,keyProperty = "id")
@Insert("insert into emp(username, name, gender, phone, job, salary, image, entry_date, dept_id, create_time, update_time) " + "VALUES (#{username},#{name},#{gender},#{phone},#{job},#{salary},#{image},#{entryDate},#{deptId},#{createTime},#{updateTime})")
void insertEmp(Emp emp);
工作经历可能有多段,需要使用foreach标签遍历插入:
<insert id="insertBatch" parameterType="list"> insert into emp_expr(emp_id, begin, end, company, job) values <foreach collection="exprList" item="expr" separator=","> (#{expr.empId},#{expr.begin},#{expr.end},#{expr.company},#{expr.job}) </foreach>
</insert>
service层优化:
@Transactional
@Override
public void addEmp(Emp emp) throws Exception { //1. 添加员工到Emp表 emp.setCreateTime(LocalDateTime.now()); emp.setUpdateTime(LocalDateTime.now()); empMapper.insertEmp(emp); log.info(String.valueOf(emp)); insertBatchEmpExprs(emp);
} @Override
@Transactional(propagation = Propagation.REQUIRED)
public void insertBatchEmpExprs(Emp emp) { //2. 添加工作经历 // CollectionUtils.isEmpty:为null或为空返回true List<EmpExpr> exprList = emp.getExprList(); if (!CollectionUtils.isEmpty(exprList)) { exprList.forEach(expr -> expr.setEmpId(emp.getId())); empExprMapper.insertBatch(exprList); }
}
insert方法还可能被复用,此处抽取为方法共service的其他方法调用,同时需要注意事务传播为REQUIRED,但是此处该方法在理论上应该是private,而不是public,但是Spring AOP不能为private方法进行增强,这也是Spring AOP的局限性,Aspectj就可以对私有/final/静态方法进行增强
文件上传
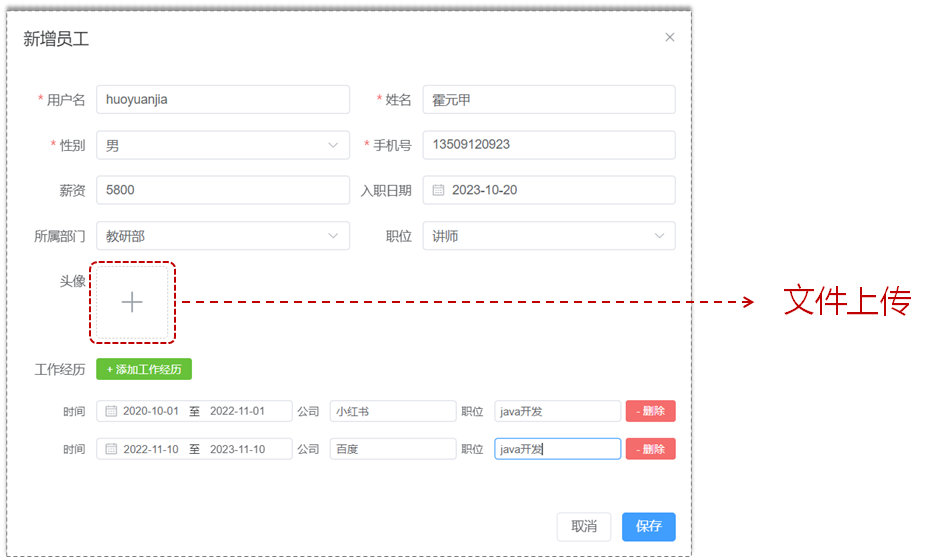
前端页面进行文件上传的三要素:
- 表单标签使用
<input type="file"> - 表单method = post
- 表单enctype = "multipart/form-data"
<form action="/upload" method="post" enctype="multipart/form-data"> 姓名: <input type="text" name="username"><br> 年龄: <input type="text" name="age"><br> 头像: <input type="file" name="file"><br> <input type="submit" value="提交">
</form>
发送的请求报文(Firefox):
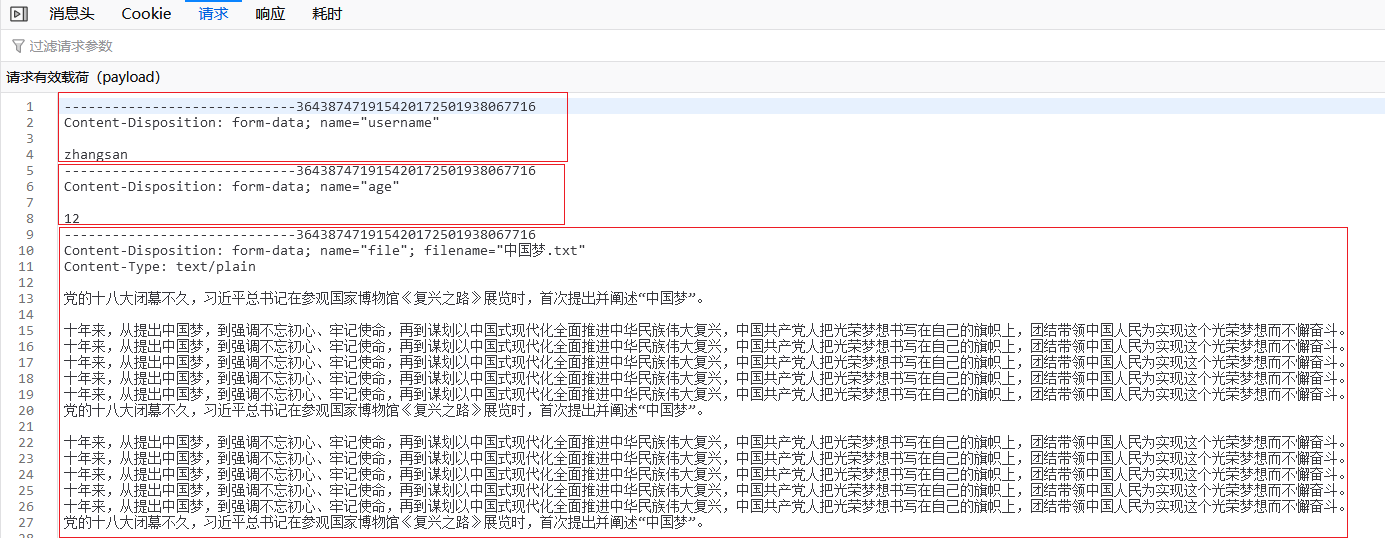
请求报文的请求体被分为三部分,分隔符是----一串数字,分隔符也会一同提交:
@Slf4j
@RestController
public class UploadTest { @PostMapping("/upload") public Result upload(String username, Integer age, MultipartFile file){ log.info("[method upload] - username : {},age : {},file : {}",username,age,file); return Result.success(); }
}
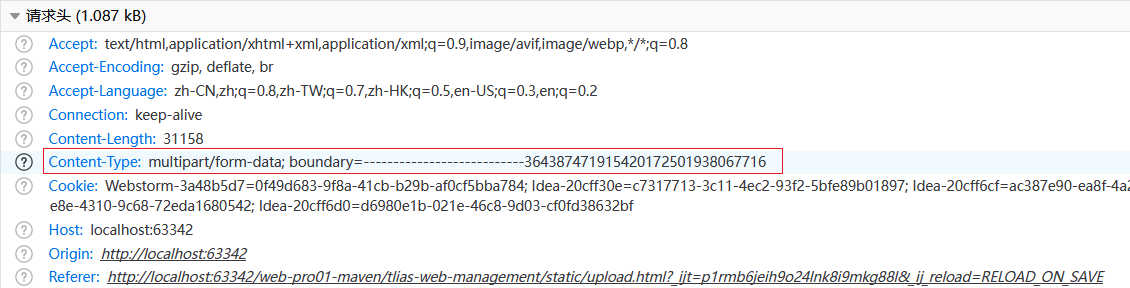
测试的时候先在log.info位置打上断点 debug启动:
上传的文件就存在此处了:

这三个.tmp文件就对应了表单中的三个部分,使用文本编辑器打开就能看到原先的内容。
以Debug启动是因为upload方法结束(响应完毕)后会将这三个文件清空,所以我们需要转储文件
转储方案:
- 本地存储
- 上传OSS
本地存储
@Slf4j
@RestController
public class UploadTest { @PostMapping("/upload") public Result upload(String username, Integer age, MultipartFile file) throws IOException { log.info("[method upload] - username : {},age : {},file : {}",username,age,file); //获取原始文件名 String filename = file.getOriginalFilename(); String parentPath = "D:\\Development\\code\\projects_to_valhalla\\web-pro01-maven\\tlias-web-management\\src\\main\\resources\\uploadfiles"; //存储到本地 file.transferTo(new File(parentPath, UUID.randomUUID() + filename.substring(filename.lastIndexOf(".")))); return Result.success(); }
}
SpringBoot文件上传时默认单个文件允许最大大小为1M,如果要上传大文件,可以进行设置:
#文件上传配置
#配置单个文件最大上传大小
spring.servlet.multipart.max-file-size=10MB
#配置单个请求最大上传大小(一次请求可以上传多个文件)
spring.servlet.multipart.max-request-size=100MBMultipartFile常用方法:

但是本地存储是有缺点的:
- 无法直接访问
- 磁盘大小限制
- 磁盘损坏数据就丢失了
OSS
使用三方服务的通用思路:
- 准备
- 参照官网SDK写入门程序
- 集成使用
参照官网SDK写入门程序:
引入依赖:
<dependency><groupId>com.aliyun.oss</groupId><artifactId>aliyun-sdk-oss</artifactId><version>3.15.1</version>
</dependency>
<dependency><groupId>javax.xml.bind</groupId><artifactId>jaxb-api</artifactId><version>2.3.1</version>
</dependency>
<dependency><groupId>javax.activation</groupId><artifactId>activation</artifactId><version>1.1.1</version>
</dependency>
<!-- no more than 2.3.3-->
<dependency><groupId>org.glassfish.jaxb</groupId><artifactId>jaxb-runtime</artifactId><version>2.3.3</version>
</dependency>
import com.aliyun.oss.ClientException;
import com.aliyun.oss.OSS;
import com.aliyun.oss.common.auth.*;
import com.aliyun.oss.OSSClientBuilder;
import com.aliyun.oss.OSSException;
import com.aliyun.oss.model.PutObjectRequest;
import com.aliyun.oss.model.PutObjectResult;
import java.io.FileInputStream;
import java.io.InputStream;public class Demo {public static void main(String[] args) throws Exception {// Endpoint以华东1(杭州)为例,其它Region请按实际情况填写。String endpoint = "https://oss-cn-hangzhou.aliyuncs.com";// 从环境变量中获取访问凭证。运行本代码示例之前,请确保已设置环境变量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。EnvironmentVariableCredentialsProvider credentialsProvider = CredentialsProviderFactory.newEnvironmentVariableCredentialsProvider();// 填写Bucket名称,例如examplebucket。String bucketName = "examplebucket";// 填写Object完整路径,完整路径中不能包含Bucket名称,例如exampledir/exampleobject.txt。String objectName = "exampledir/exampleobject.txt";// 填写本地文件的完整路径,例如D:\\localpath\\examplefile.txt。// 如果未指定本地路径,则默认从示例程序所属项目对应本地路径中上传文件流。String filePath= "D:\\localpath\\examplefile.txt";// 创建OSSClient实例。OSS ossClient = new OSSClientBuilder().build(endpoint, credentialsProvider);try {InputStream inputStream = new FileInputStream(filePath);// 创建PutObjectRequest对象。PutObjectRequest putObjectRequest = new PutObjectRequest(bucketName, objectName, inputStream);// 创建PutObject请求。PutObjectResult result = ossClient.putObject(putObjectRequest);} catch (OSSException oe) {System.out.println("Caught an OSSException, which means your request made it to OSS, "+ "but was rejected with an error response for some reason.");System.out.println("Error Message:" + oe.getErrorMessage());System.out.println("Error Code:" + oe.getErrorCode());System.out.println("Request ID:" + oe.getRequestId());System.out.println("Host ID:" + oe.getHostId());} catch (ClientException ce) {System.out.println("Caught an ClientException, which means the client encountered "+ "a serious internal problem while trying to communicate with OSS, "+ "such as not being able to access the network.");System.out.println("Error Message:" + ce.getMessage());} finally {if (ossClient != null) {ossClient.shutdown();}}}
}
封装OSS工具类
@Slf4j
public class AliyunOSSUtils { /** * 上传文件 * @param endpoint endpoint域名 * @param bucketName 存储空间的名字 * @param content 内容字节数组 */ public static String upload(String endpoint, String bucketName, byte[] content, String extName) throws Exception { // 从环境变量中获取访问凭证。运行本代码示例之前,请确保已设置环境变量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。 EnvironmentVariableCredentialsProvider credentialsProvider = CredentialsProviderFactory.newEnvironmentVariableCredentialsProvider(); // 填写Object完整路径,完整路径中不能包含Bucket名称,例如exampledir/exampleobject.txt。 String objectName = UUID.randomUUID() + extName; // 创建OSSClient实例。 OSS ossClient = new OSSClientBuilder().build(endpoint, credentialsProvider); try { // 创建PutObjectRequest对象。 PutObjectRequest putObjectRequest = new PutObjectRequest(bucketName, objectName, new ByteArrayInputStream(content)); // 创建PutObject请求。 PutObjectResult result = ossClient.putObject(putObjectRequest); } catch (OSSException oe) { log.error("Caught an OSSException, which means your request made it to OSS, but was rejected with an error response for some reason."); log.error("Error Message:" + oe.getErrorMessage()); log.error("Error Code:" + oe.getErrorCode()); log.error("Request ID:" + oe.getRequestId()); log.error("Host ID:" + oe.getHostId()); } catch (ClientException ce) { log.error("Caught an ClientException, which means the client encountered a serious internal problem while trying to communicate with OSS, such as not being able to access the network."); log.error("Error Message:" + ce.getMessage()); } finally { if (ossClient != null) { ossClient.shutdown(); } } return endpoint.split("//")[0] + "//" + bucketName + "." + endpoint.split("//")[1] + "/" + objectName; } }
最终的文件上传流程:
application.yml:
spring: servlet: multipart: max-file-size: 10MB max-request-size: 100MB config: import: classpath:conf/mybatis-conf.yml,classpath:conf/aliyun-oss-config.yml # 配置spring事务管理器的日志为true
logging: level: org.springframework.jdbc.support.JdbcTransactionManager: debug
aliyun-oss-conf.yml:
aliyun: oss: endpoint: https://oss-cn-beijing.aliyuncs.com bucketName: web-tlias-eun
定义属性类,配置文件属性注入该类:
@Data
@Component
@ConfigurationProperties(prefix = "aliyun.oss")
public class AliyunOSSProperties { private String endpoint; private String bucketName;
}
使用的时候只需要注入就可以了:
@Slf4j
@RestController
public class UploadController {
/* @Value("${aliyun.oss.endpoint}") private String endPoint; @Value("${aliyun.oss.bucketName}") private String bucketName;*/ @Autowired private AliyunOSSProperties aliyunOSSProperties; @PostMapping("/upload") public Result upload(MultipartFile file) throws Exception { String filename = file.getOriginalFilename(); log.info("[文件上传] - file : {}", filename); String extName = filename.substring(filename.lastIndexOf(".")); String url = AliyunOSSUtils.upload(aliyunOSSProperties.getEndpoint(),aliyunOSSProperties.getBucketName(), file.getBytes(), extName); return Result.success(url); }
}
属性类可能有提示:

只需要再引入一个依赖即可:
这个依赖就是在先写属性类再写yml文件时可以有提示。
重新思考本需求
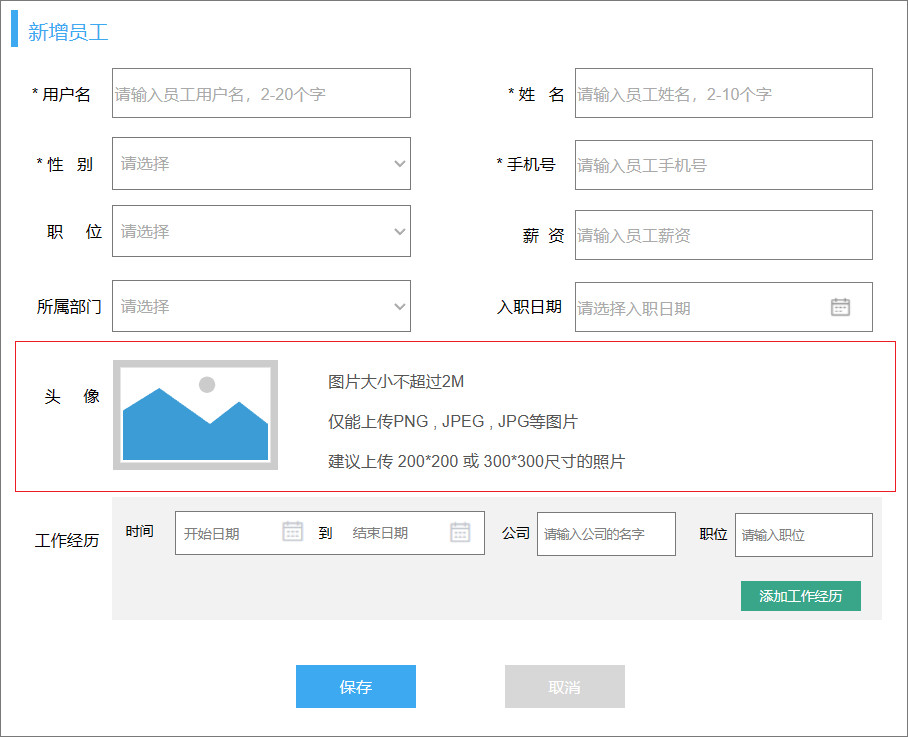
选择完头像后,访问UploadController {POST /upload} 上传图片,并将URL地址返回到此处
但是可能存在的情况:用户选择完头像后点击取消,这条数据没有保存在数据库中而OSS中还有这张图片;或者用户选择完头像后又选择了另外一张,第一次选择的图片也会存在于OSS之内。
解决办法:定时任务扫描数据库中所有URL地址,和OSS的地址做差集,清除OSS中所有差集元素。
删
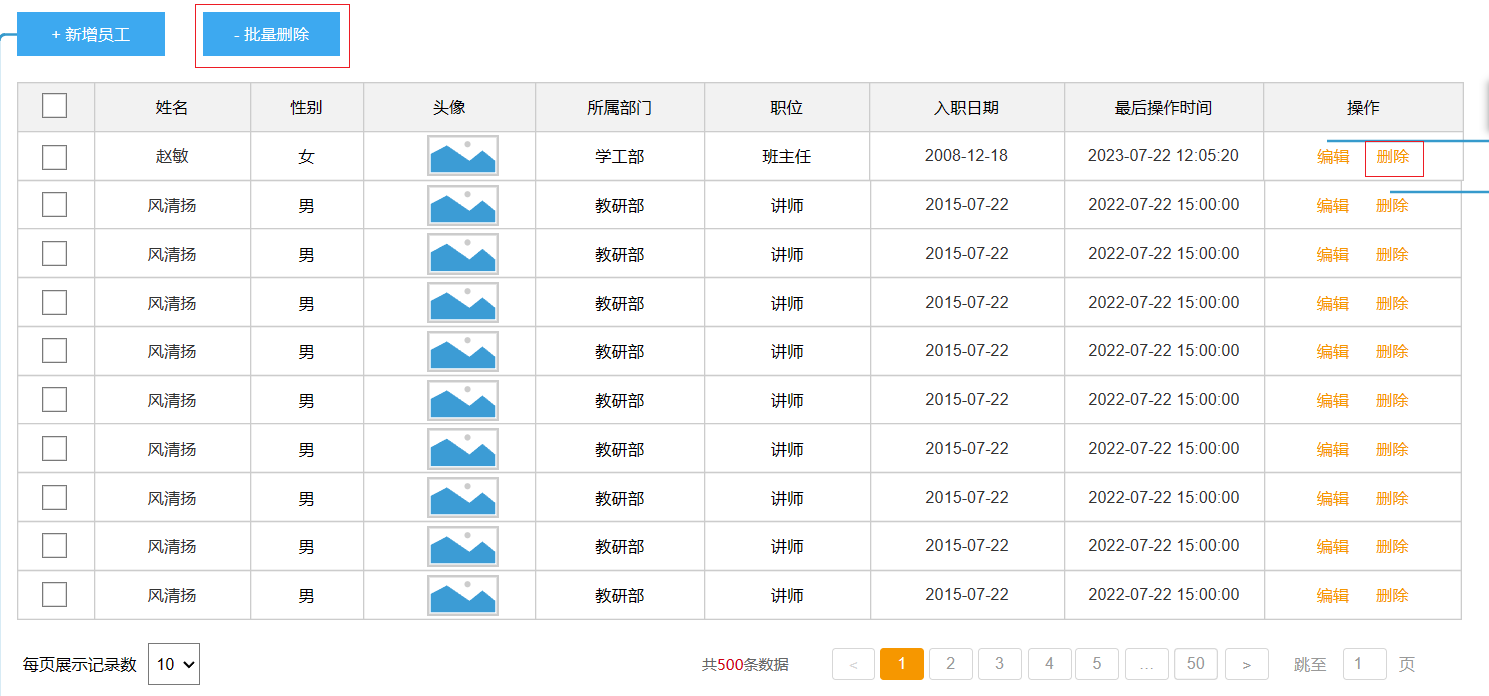
删除分为:批量删除和单个删除,其实单个删除就是特殊的批量删除,可以只定义一个接口。
删除的实现方式:
- 前端传递JSON数组,每一个元素是要删除的emp id和OSS的图片地址, 后端收到请求后,删除EMP表中id = id的记录,再删除EMP_EXPR表中emp_id = id的记录;异步删除OSS中的图片
但是目前的前端只传递了ID,如果要删除OSS的图片就要从数据库里查出来对应的image url,也就是先查询完毕才能再删除
接口文档:
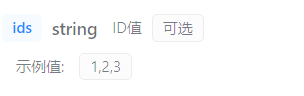
前端传递的数据格式是 ids=1,2,3,应该使用数组或List集合接收
Controller使用List集合接收:
@DeleteMapping
public Result delete(@RequestParam List<Integer> ids) throws Exception { //同步查询URLList<String> urls = empService.queryURLByIds(ids); //异步删除OSS fileController.delete(urls); //同步删除数据库 empService.removeByIds(ids); return Result.success();
}
Service:
@Override
public void removeByIds(List<Integer> ids) { //删除emp表数据 empMapper.deleteByIds(ids); //删除emp_expr表数据 empExprMapper.deleteByEmpIds(ids);
}
改
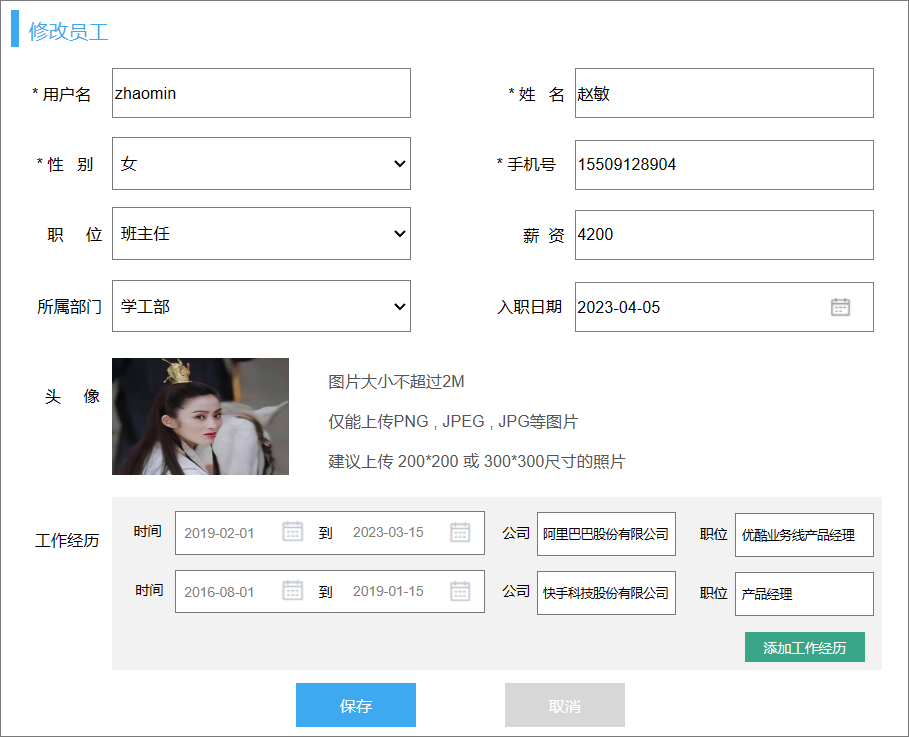
修改分为两部分:
- 点击修改按钮,根据id查询数据
- 点击保存,保存修改后的数据
数据回显

响应数据示例:
{ "code": 0, "msg": "string", "data": { "id": 0, "username": "string", "password": "string", "name": "string", "gender": 0, "job": 0, "salary": 0, "image": "string", "entryDate": "2019-08-24", "deptId": 0, "createTime": "2019-08-24T14:15:22Z", "updateTime": "2019-08-24T14:15:22Z", "exprList": [ { "id": 1, "begin": "2019-08-24", "end": "2019-08-24", "company": "string", "job": "string", "empId": 0 } ] }}
Controller:
@GetMapping("/{id}")
public Result queryById(@PathVariable Integer id){ Emp emp = empService.queryById(id); return Result.success(emp);
}
Service:
@GetMapping("/{id}")
public Result queryById(@PathVariable Integer id){ Emp emp = empService.queryById(id); return Result.success(emp);
}
Mapper:
<select id="selectById" resultType="com.itheima.model.pojo.Emp"> select e.*, ee.id ee_id, ee.begin ee_begin, ee.end ee_end, ee.company ee_company, ee.job ee_job, ee.emp_id ee_emp_id from emp e left join emp_expr ee on e.id = ee.emp_id where e.id = #{id}
</select>
这样是不行的,因为表连接时,emp表的一条记录会对应emp_expr的多条记录,此时就需要使用多对一映射:
<resultMap id="empResultMap" type="com.itheima.model.pojo.Emp" > <id column="id" property="id"/> <result column="username" property="username" /> <result column="password" property="password" /> <result column="name" property="name" /> <result column="gender" property="gender" /> <result column="phone" property="phone" /> <result column="job" property="job" /> <result column="salary" property="salary" /> <result column="image" property="image" /> <result column="entry_date" property="entryDate" /> <result column="dept_id" property="deptId" /> <result column="create_time" property="createTime" /> <result column="update_time" property="updateTime" /> <collection property="exprList" ofType="com.itheima.model.pojo.EmpExpr"> <id column="ee_id" property="id" /> <result column="ee_begin" property="begin" /> <result column="ee_end" property="end" /> <result column="ee_company" property="company" /> <result column="ee_job" property="job" /> <result column="ee_emp_id" property="empId" /> </collection>
</resultMap><select id="selectById" resultMap="empResultMap" > select e.*, ee.id ee_id, ee.begin ee_begin, ee.end ee_end, ee.company ee_company, ee.job ee_job, ee.emp_id ee_emp_id from emp e left join emp_expr ee on e.id = ee.emp_id where e.id = #{id}
</select>
思考:响应update_time是页面展示的要求,响应create_time是为什么?
为了在下文提交修改的json数据时携带。但似乎这是没有意义的。
修改
请求参数:
{ "id": 0, "username": "string", "password": "string", "name": "string", "gender": 0, "job": 0, "image": "string", "entryDate": "2019-08-24", "salary": 0, "deptId": 0, "createTime": "2019-08-24T14:15:22Z", "updateTime": "2019-08-24T14:15:22Z", "exprList": [ { "id": 1, "begin": "2019-08-24", "end": "2019-08-24", "company": "string", "job": "string", "empId": 0 } ]}
Controller:
@PutMapping
public Result modifyEmp(@RequestBody Emp emp){ empService.modifyEmpById(emp); return Result.success();
}
service:
@Override
public void modifyEmpById(Emp emp) { emp.setUpdateTime(LocalDateTime.now()); //更新员工表信息 empMapper.updateById(emp); }
mapper:
修改的字段取决于接口文档:
<update id="updateById"> update emp <set> <if test="username != null and username != ''">username = #{username},</if> <if test="name != null and name != ''">name = #{name},</if> <if test="gender != null">gender = #{gender},</if> image = #{image}, dept_id = #{deptId}, entry_date = #{entryDate}, job = #{job}, salary = #{salary} </set> where id = #{id}
</update>
接下来是service的第二部分:更新工作经历
但是工作经历有其特殊性,此处如果要更新有两种方法:
- 前端只传递修改的和新增的工作经历,后端判断是否有id,有id就update,无id就insert
- 点击保存,传递所有工作经历,点击保存后先把原先的工作经历delete,再insert新的工作经历
对比两种实现:
第一种方法:如果要删除工作经历,还需要一个根据id删除的接口,点击一个删除一次,对应了deleteById这条语句,但是删除员工工作经历的操作较少;后端保存员工工作经历信息需要 对id有无进行分别处理,这需要两条SQL语句,也就是两次数据库连接。
第二种方法:后端只需要delete和insert,如果删除的话,只需要执行delete,如果新增 + 修改还是两条SQL语句
但是对于工作经历来说,一般情况下修改时只有新增的操作,第一种方法可以只执行一条SQL语句,第二种方法需要执行两条SQL语句;如果修改时要修改工作经历内容,第一种方法要执行两条SQL语句,第二种方法也是两条SQL语句,但是明显第二种方法需要处理的数据量更多,第一种方法其实更好。
本例前端传递的是所有的工作经历,只能采用第二种方法
Service:
@Transactional
@Override
public void modifyEmpById(Emp emp) { emp.setUpdateTime(LocalDateTime.now()); //更新员工表信息 empMapper.updateById(emp); //更新工作经历 // 1. 删除 // 2. 新增 empExprMapper.deleteByEmpIds(List.of(emp.getId())); List<EmpExpr> exprList = emp.getExprList(); if (!CollectionUtils.isEmpty(exprList)){ empExprMapper.insertBatch(exprList); }
}
注意:此处insert工作经历时没有遍历再赋值emp_id,因为前端传递的exprList中应当对所有的expr进行赋值,所有的expr都属于当前的员工,但遗憾的是前端并没有赋值,我们还需要多一次操作:
@Transactional
@Override
public void modifyEmpById(Emp emp) { emp.setUpdateTime(LocalDateTime.now()); //更新员工表信息 empMapper.updateById(emp); //更新工作经历 // 1. 删除 // 2. 新增 empExprMapper.deleteByEmpIds(List.of(emp.getId())); List<EmpExpr> exprList = emp.getExprList(); if (!CollectionUtils.isEmpty(exprList)){ exprList.forEach(expr -> expr.setEmpId(emp.getId())); empExprMapper.insertBatch(exprList); }
}
此处的插入工作经历和新增用户时插入工作经历完全相同,可以抽取为方法:
@Transactional
@Override
public void modifyEmpById(Emp emp) { emp.setUpdateTime(LocalDateTime.now()); //更新员工表信息 empMapper.updateById(emp); //更新工作经历 // 1. 删除 // 2. 新增 empExprMapper.deleteByEmpIds(List.of(emp.getId())); insertBatchEmpExprs(emp);
}@Override
@Transactional(propagation = Propagation.REQUIRED)
public void insertBatchEmpExprs(Emp emp) { //2. 添加工作经历 // CollectionUtils.isEmpty:为null或为空返回true List<EmpExpr> exprList = emp.getExprList(); if (!CollectionUtils.isEmpty(exprList)) { exprList.forEach(expr -> expr.setEmpId(emp.getId())); empExprMapper.insertBatch(exprList); }
}
报表数据
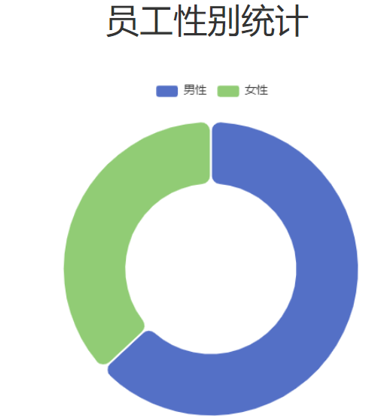
性别统计
响应数据:
参数格式:application/json
参数说明:
| 参数名 | 类型 | 是否必须 | 备注 |
|---|---|---|---|
| code | number | 必须 | 响应码,1 代表成功,0 代表失败 |
| msg | string | 非必须 | 提示信息 |
| data | List | 非必须 | 返回的数据 |
| |- name | string | 非必须 | 性别 |
| |- value | number | 非必须 | 人数 |
示例:
{"code": 1,"msg": "success","data": [{"name": "男性员工","value": 5},{"name": "女性员工","value": 6}]
}
分析各层职责:
-
Controller:简单
-
Service:简单
-
Mapper:根据gender进行分组,统计男性和女性
问题在于Mapper的结果如何封装?
- 常规做法,封装为pojo类
List<GenderOptions> selectGenderCount();
但是这个pojo类似乎是没有意义的,查询的数据过于简单,如果类似的查询都封装为pojo可能会导致类爆炸
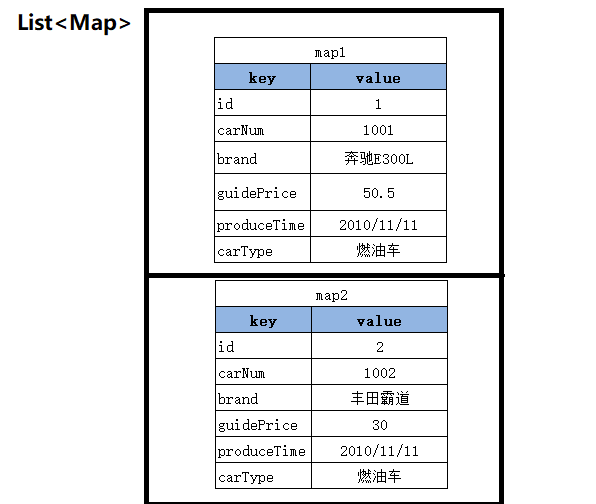
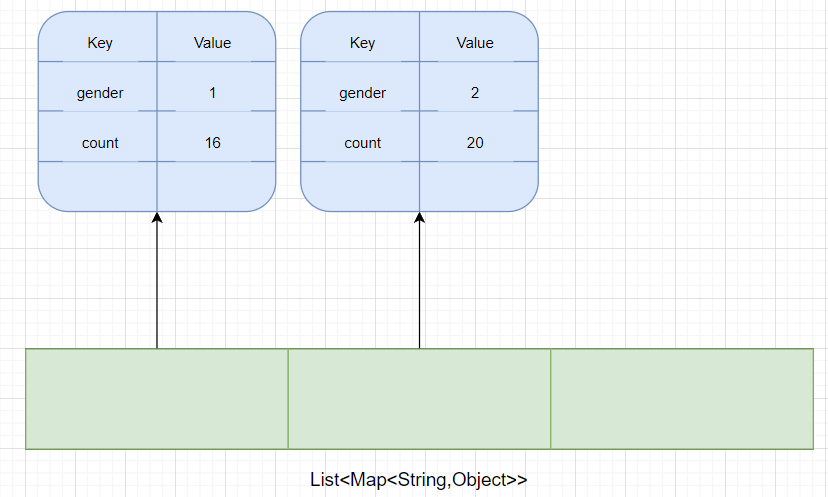
- 封装为Map集合
List<Map<String,Object>> selectGenderCount();
Map集合用来代替pojo类,List中Map集合的个数即为查询出的记录条数,而Map集合中的键值对的个数即为每条记录中字段的个数,key为字段名,value为字段值。
key一定是string类型的字段名,而value可能是string/integer的字段值
<select id="selectGenderCount" resultType="java.util.Map"> select IF(gender=1,'男性员工','女性员工') name, count(*) value from emp group by gender;
</select>
查询的结果:
!
注意在Mapper接口中:
@MapKey("id")
List<Map<String,Object>> selectGenderCount();
需要指定@MapKey,这其实是MybatisX插件的误报,指定MapKey是在返回Map<Object,Map<String,Object>>时需要指定外层Map的id
员工职位统计
参数格式:application/json
参数说明:
| 参数名 | 类型 | 是否必须 | 备注 |
|---|---|---|---|
| code | number | 必须 | 响应码,1 代表成功,0 代表失败 |
| msg | string | 非必须 | 提示信息 |
| data | object | 非必须 | 返回的数据 |
| |- jobList | string[] | 必须 | 职位列表 |
| |- dataList | number[] | 必须 | 人数列表 |
{"code": 1,"msg": "success","data": {"jobList": ["教研主管","学工主管","其他","班主任","咨询师","讲师"],"dataList": [1,1,2,6,8,13]}
}
与上例不同的是,上例中的data:
{"code": 1,"msg": "success","data": [{"name": "男性员工","value": 5},{"name": "女性员工","value": 6}]
}
这是List<Map<String,Object>>,而本例中返回了一个对象:
@Data
@NoArgsConstructor
@AllArgsConstructor
public class JobOptions { private List<String> jobList; private List<Integer> dataList;
}
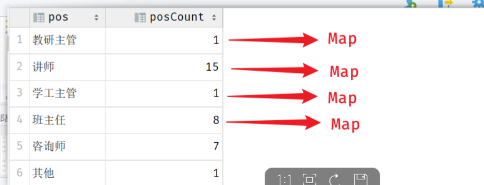
SQL语句查询的单条结果还是以Map封装,key为职位信息,value为该职位对应的员工数量:
<select id="selectJobCount" resultType="java.util.Map"> select case job when 1 then '班主任' when 2 then '讲师' when 3 then '学工主管' when 4 then '教研主管' when 5 then '咨询师' else '?' end job,count(*) jobCountfrom emp where job is not null group by job;
</select>
不过有两种封装结果集:
-
List<Map<String,Object>>:不需要指定@MapKey -
Map<String,Map<String,Object>>:需要指定@MapKey
最终的结果都是要从结果集中将entry的key作为JobOptions的jobList,value作为dataList,这两中封装方式对应了两种处理方式:
List<Map<String,Object>>
@Override
public JobOptions queryJobCount() { List<Map<String, Object>> listMaps = empMapper.selectJobCount(); List<String> jobs = listMaps.stream().map(map -> String.valueOf(map.get("job"))).toList(); List<Integer> jobCount = listMaps.stream().map(map -> Integer.parseInt(map.get("jobCount").toString())).toList(); return new JobOptions(jobs,jobCount);
}
Map<String,Map<String,Object>>
@MapKey("job")
Map<String,Map<String,Object>> selectJobCount();
指定了key为查询的job字段值,value为Map,该Map的key为字段名,value为字段值
@Override
public JobOptions queryJobCount() { Map<String,Map<String, Object>> mapMap = empMapper.selectJobCount(); List<Integer> jobCount = new ArrayList<>(); List<String> jobs = new ArrayList<>(); System.out.println(mapMap); mapMap.forEach((key,mapValue) -> { jobs.add(key); jobCount.add(Integer.parseInt(mapValue.get("jobCount").toString())); }); return new JobOptions(jobs,jobCount);
}
异常处理
当前程序执行的流程不可避免的出现各类异常:

但是出现异常的返回结果不符合规范:
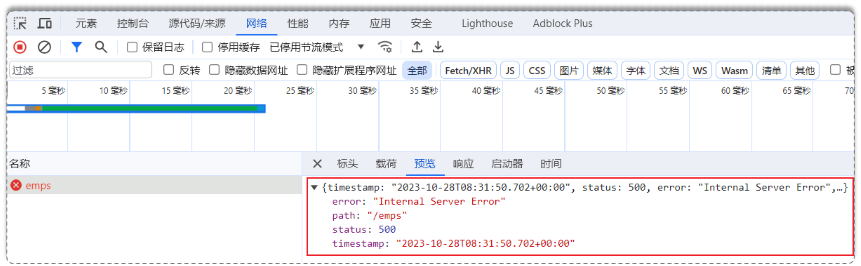
不管是成功还是失败都应该返回这个结果:
前端接口也是根据这个格式来解析数据的。
目前我们没有对异常进行任何处理,SpringBoot遇到异常后自动以该格式返回给浏览器:
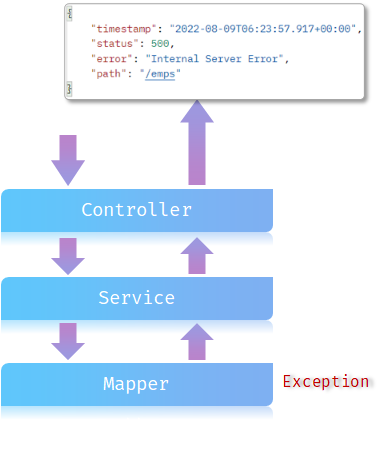
处理异常的方式:
- 在Controller中try-catch
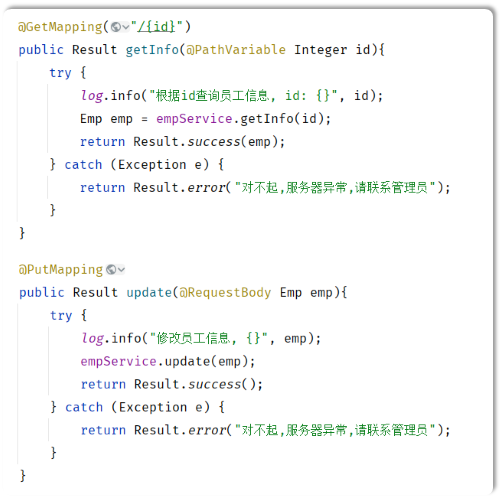
- 全局异常处理器:
@Slf4j
@RestControllerAdvice //声明此类为异常处理器
public class GlobalExceptionHandler { @ExceptionHandler //声明此方法为异常处理方法 public Result handler(Exception e){ log.error("全局异常处理器 : ",e); return Result.error(String.valueOf(e.getClass())); }
}
这样就改变了异常的抛出过程:
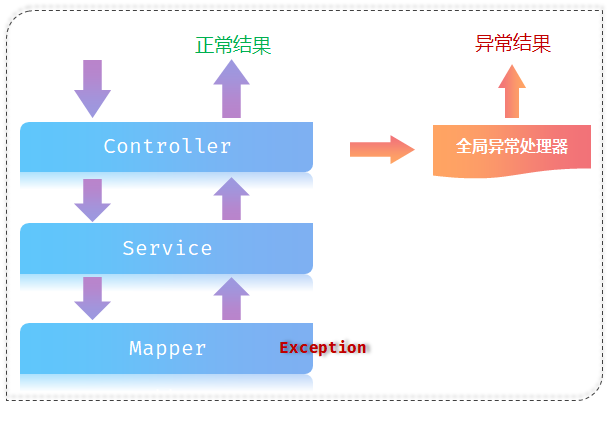
@RestControllerAdvice = @ControllerAdvice + @ResponseBody
注意:如果定义小范围和大范围的异常处理方法,优先被小范围处理
Clazz的增删改查
查
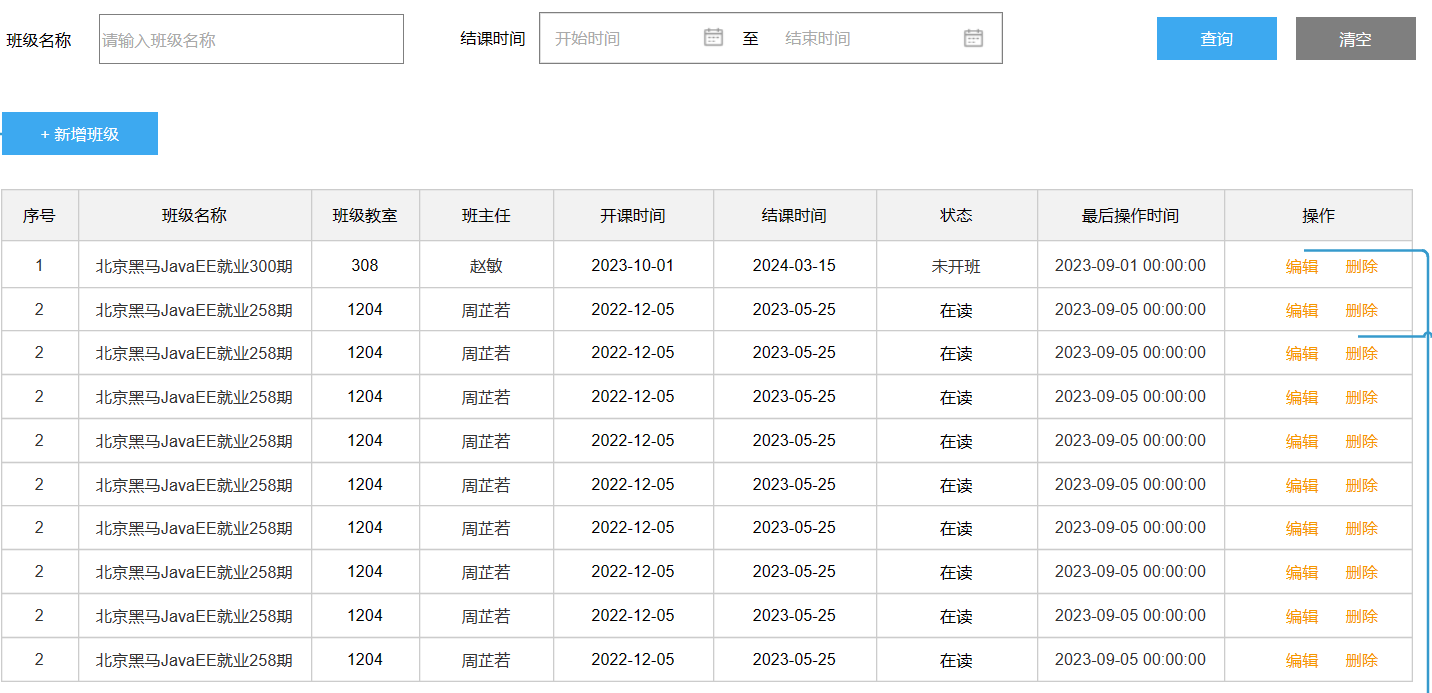
条件分页查询,参数:
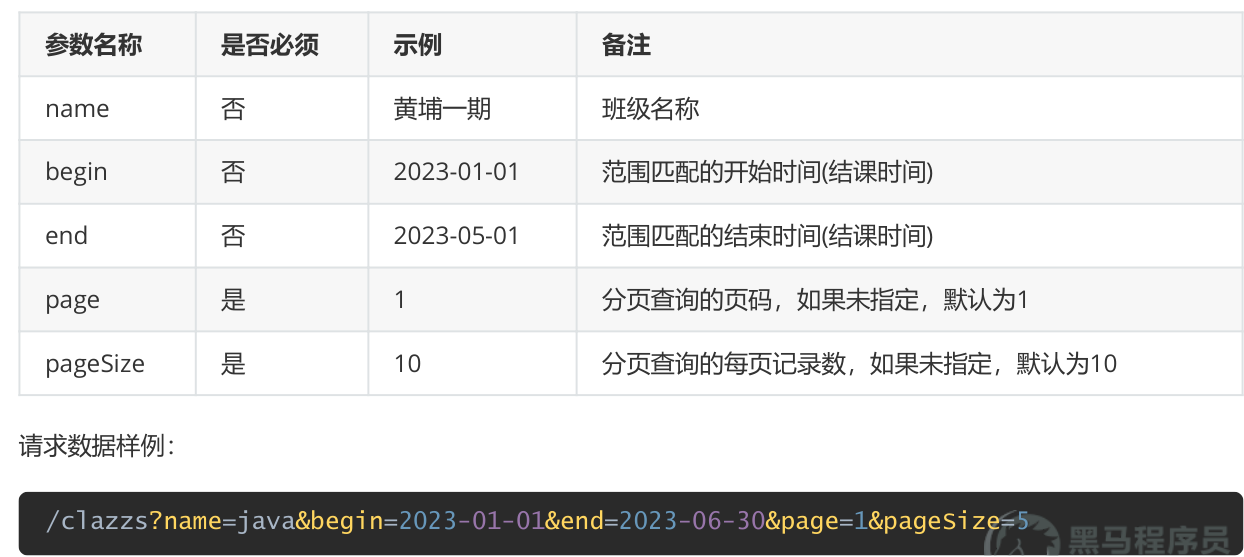
响应数据:
{ "code": 1, "msg": "success", "data": { "total": 6, "rows": [ { "id": 7, "name": "黄埔四期", "room": "209", "beginDate": "2023-08-01", "endDate": "2024-02-15", "masterId": 7, "createTime": "2023-06-01T17:51:21", "updateTime": "2023-06-01T17:51:21", "masterName": "纪晓芙" }, { "id": 6, "name": "JavaEE就业166期", "room": "105", "beginDate": "2023-07-20", "endDate": "2024-02-20", "masterId": 20, "createTime": "2023-06-01T17:46:10", "updateTime": "2023-06-01T17:46:10", "masterName": "陈友谅" } ] }
}
masterName需要连接emp表查询,正常情况下,班级状态应该在前端计算,遗憾的是本例前端没有计算,只能我们计算
计算方式:
- service层查询结果后,进行计算
- SQL语句直接计算
<select id="selectByPage" resultType="com.itheima.model.pojo.Clazz"> select c.*, e.name master_name, case when now() > c.end_date then '结课' when now() < c.begin_date then '未开班' else '开班' end status from clazz c left join emp e on c.master_id = e.id <where> <if test="name != null and name != ''">name like concat('%',#{name},'%')</if> <if test="begin != null and end != null">and end_date between #{begin} and #{end}</if> </where> order by c.update_time desc
</select>
注意:xml文件中的> <看作标签的开始或结束,就会匹配到某些标签导致xml结构混乱,应该使用实体符号代替
删
很简单
增
界面原型:
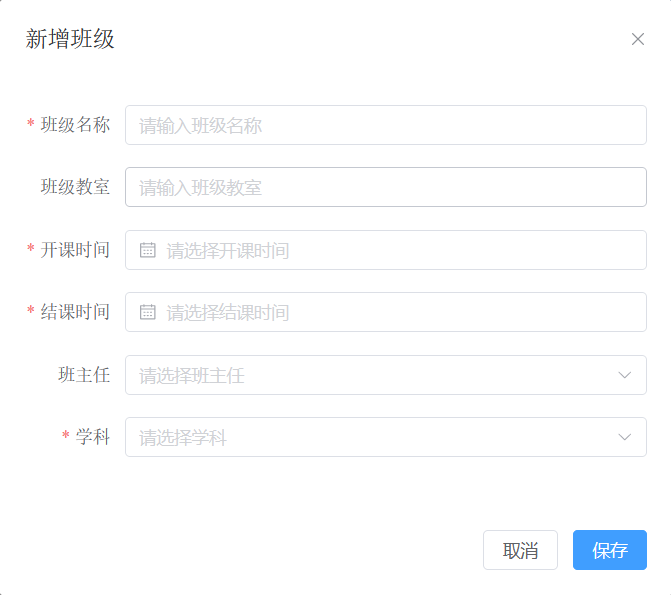
班主任是下拉列表,点击新增按钮之后应该先查出所有的班主任,定义在EmpController中
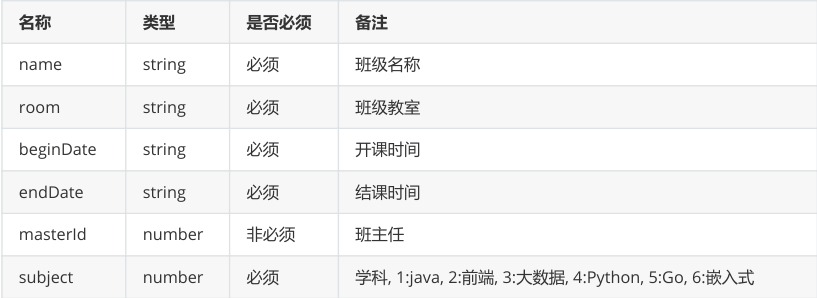
再做新增班级的接口:

改
改还是两部,数据回显和update
查所有
很简单
Student的增删改查

展示的时候往往都希望最后修改的在最前面,就需要根据update_time倒序排列
登录
请求参数:

请求参数可以用Emp封装
响应给用户的信息应该包含token,响应数据:
{"code": 1,"msg": "success","data": {"id": 2,"username": "songjiang","name": "宋江","token":"eyJhbGciOiJIUzI1NiJ9.eyJpZCI6MiwidXNlcm5hbWUiOiJzb25namlhbmciLCJleHAiOjE2OTg3MDE3NjJ9.w06EkRXTep6SrvMns3w5RKe79nxauDe7fdMhBLK-MKY"}
}
根据id标识用户唯一身份,应该在token中包含id
响应数据可以封装在LogInfo中:
@Data
@AllArgsConstructor
@NoArgsConstructor
@Accessors(chain = true)
public class LogInfo { private Integer id; private String name; private String username; private String token;
}
Controller:
@PostMapping("/login")
public Result login(@RequestBody Emp emp){ LogInfo logInfo = empService.queryByUsernameAndPwd(emp); //JWT return logInfo == null ? Result.error("用户名或密码错误") : Result.success(logInfo);
}
Service:
@Override
public LogInfo queryByUsernameAndPwd(Emp emp) { LogInfo logInfo = empMapper.selectByUsernameAndPwd(emp); if (logInfo == null){ return null; } HashMap<String, Object> hashMap = new HashMap<>() {{ put("id",logInfo.getId()); put("username",logInfo.getUsername()); put("name",logInfo.getName()); }}; return logInfo.setToken(JwtUtils.generateJwt(hashMap)); //chain
}
直接封装为LogInfo,但是要保证查询结果列名和Emp的属性名一致。
Mapper:
@Select("select * from emp where username = #{username} and password = #{password}")
LogInfo selectByUsernameAndPwd(Emp emp);
工具类:
public class JwtUtils { private static String signKey = "SVRIRUlNQQ=="; private static Long expire = 43200000L; /** * 生成JWT令牌 * @return */ public static String generateJwt(Map<String,Object> claims){ String jwt = Jwts.builder() .addClaims(claims) .signWith(SignatureAlgorithm.HS256, signKey) .setExpiration(new Date(System.currentTimeMillis() + expire)) .compact(); return jwt; } /** * 解析JWT令牌 * @param jwt JWT令牌 * @return JWT第二部分负载 payload 中存储的内容 */ public static Claims parseJWT(String jwt){ Claims claims = Jwts.parser() .setSigningKey(signKey) .parseClaimsJws(jwt) .getBody(); return claims; }
}
至此已经完成了登录功能。
登录校验
用户访问接口时应该对用户身份进行校验,如果是登录用户才能访问系统接口,未登录的用户响应401
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { try { String token = request.getHeader("token"); //未携带token if (!StringUtils.hasLength(token)) { response.setStatus(401);throw new RuntimeException(); } //token被篡改,抛出异常 JwtUtils.parseJWT(token); //携带了token,并且校验通过 return true; } catch (Exception e) { e.printStackTrace(); response.setStatus(401); return false; } }
如果在Interceptor中出现异常,后续的方法无法执行,目标方法无法执行,异常上抛到全局异常处理器
记录操作日志
create table operate_log
( id int unsigned auto_increment comment 'ID' primary key, operate_emp_id int unsigned null comment '操作人ID', operate_time datetime null comment '操作时间', class_name varchar(100) null comment '操作的类名', method_name varchar(100) null comment '操作的方法名', method_params varchar(1000) null comment '方法参数', return_value varchar(2000) null comment '返回值', cost_time int null comment '方法执行耗时, 单位:ms'
) comment '操作日志表';
ORM:
@Data
@Accessors(chain = true)
@NoArgsConstructor
@AllArgsConstructor
public class OperateLog { private Integer id; //ID private Integer operateEmpId; //操作人ID private LocalDateTime operateTime; //操作时间 private String className; //操作类名 private String methodName; //操作方法名 private String methodParams; //操作方法参数 private String returnValue; //操作方法返回值 private Long costTime; //操作耗时 private String operateEmpName;
}
@Aspect
@Component
public class OperateLogAspectj { @Autowired private OperateLogMapper operateLogMapper; @Autowired private HttpServletRequest request; @Autowired private ObjectMapper objectMapper; @Around("@annotation(com.itheima.anno.Log)") public Object aroundAdvice(ProceedingJoinPoint joinPoint) throws Throwable { String token = request.getHeader("token"); Integer operateEmpId = JwtUtils.parseParam(token, "id", Integer.class); String operateEmpName = JwtUtils.parseParam(token, "name", String.class); LocalDateTime operateTime = LocalDateTime.now(); String className = joinPoint.getTarget().getClass().getName(); String methodName = joinPoint.getSignature().getName(); String methodParams = objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(joinPoint.getArgs()); long begin = System.currentTimeMillis(); Object proceed = joinPoint.proceed(); String returnValue = objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(proceed); long end = System.currentTimeMillis(); OperateLog operateLog = new OperateLog().setOperateEmpId(operateEmpId) .setOperateTime(operateTime) .setClassName(className) .setMethodName(methodName) .setMethodParams(methodParams) .setReturnValue(returnValue).setCostTime(end - begin); operateLogMapper.insert(operateLog); return proceed; }
}
如果在切面中出现异常,递时异常会导致chain无法向下推进,执行不到目标方法。
记录登录日志
需求:
记录当前 tlias 智能学习辅助系统中所有员工的登录操作 (切入点:execution(....); 通知类型:@Around) ,无论登录成功还是失败,都需要记录日志。日志信息包含如下信息:
- 用户名 (登录时,输入的用户名) ----- 【提示:用户名在原始方法执行时的参数中 -- 可以强转】
- 密码 (登录时,输入的密码) -------- 【提示:密码在原始方法执行时的参数中 】
- 操作时间 (什么时间,员工登录的)
- 登录是否成功 ------ 【提示:在原始方法执行后的返回值中,可以通过Result来获取code从而判断成功还是失败 -- 可以强转】
- 登录成功后,下发的jwt令牌 ------ 【提示:jwt在原始方法执行后的返回值中 -- 可以强转】
- 登录操作耗时
-- 登录日志表
create table emp_login_log(id int unsigned primary key auto_increment comment 'ID',username varchar(20) comment '用户名',password varchar(32) comment '密码',login_time datetime comment '登录时间',is_success tinyint unsigned comment '是否成功, 1:成功, 0:失败',jwt varchar(1000) comment 'JWT令牌',cost_time bigint unsigned comment '耗时, 单位:ms'
) comment '登录日志表';
package com.itheima.pojo;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;import java.time.LocalDateTime;@Data
@NoArgsConstructor
@AllArgsConstructor
public class EmpLoginLog {private Integer id; //IDprivate String username; //登录用户名private String password; //登录密码private LocalDateTime loginTime; //登录时间private Short isSuccess; //是否登录成功, 1:成功, 0:失败private String jwt; //成功后, 下发的JWT令牌private Long costTime; //登录耗时, 单位:ms
}
@Slf4j
@Aspect
@Component
public class LoginLogAspect { @Autowired private EmpLoginLogMapper loginLogMapper; @Around("execution(* com.itheima.controller.LoginController.login(com.itheima.model.pojo.entity.Emp))") public Object around(ProceedingJoinPoint joinPoint) throws Throwable { Result result = null; if (joinPoint.getArgs()[0] instanceof Emp emp){ String username = emp.getUsername(); String password = emp.getPassword(); LocalDateTime now = LocalDateTime.now(); long begin = System.currentTimeMillis(); result = (Result) joinPoint.proceed(); long costTime = System.currentTimeMillis() - begin; short isSuccess = 0; String jwt = null; if (result.getData() instanceof LogInfo logInfo){ isSuccess = 1; jwt = logInfo.getToken(); } EmpLoginLog empLoginLog = new EmpLoginLog(null, username, password, now, isSuccess, jwt, costTime); log.info("员工登录信息:{}",empLoginLog); loginLogMapper.insert(empLoginLog); } return result; } }
总结