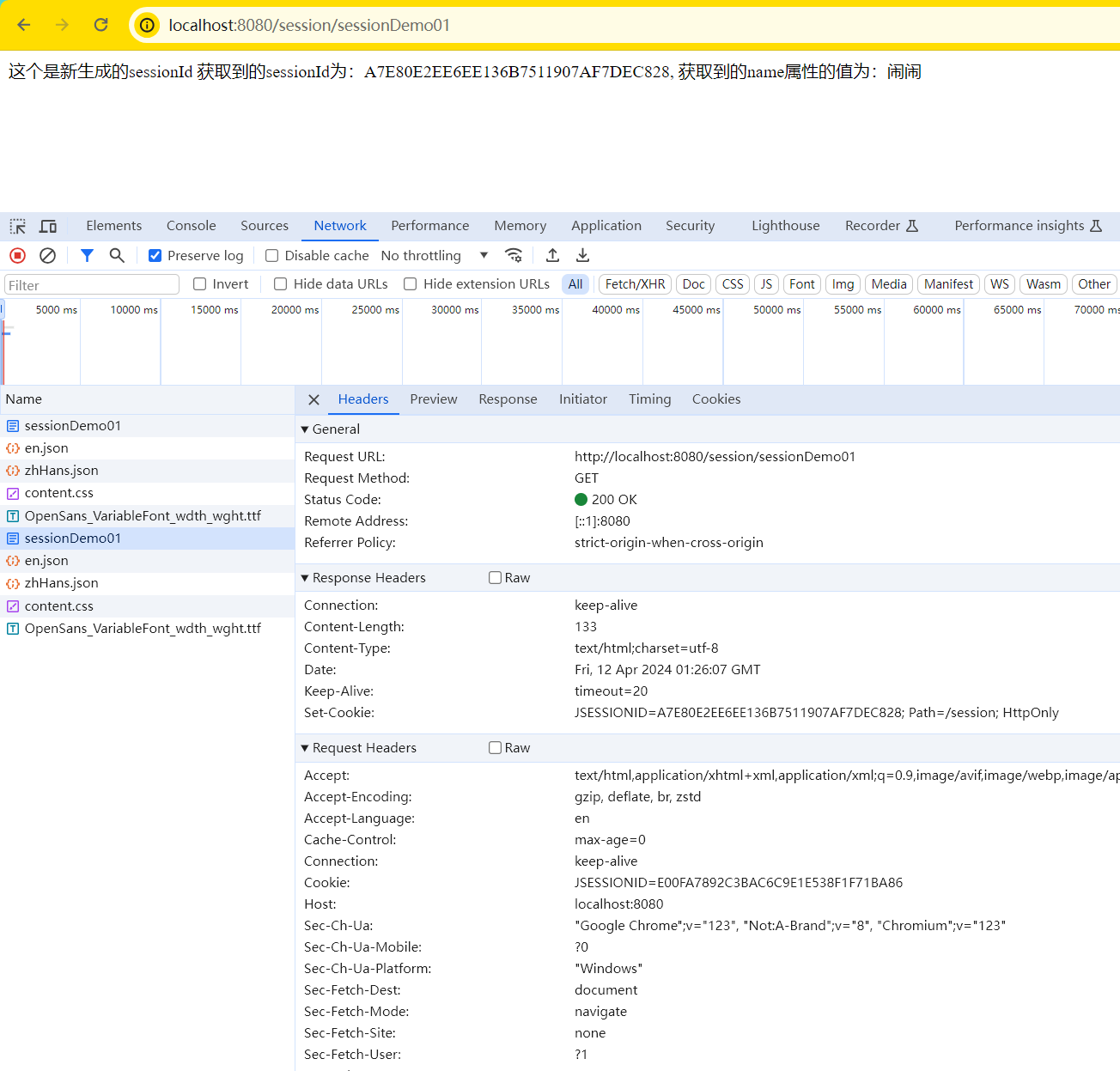
背景:
我有一个列表,列表中存储的子元素是字典,字典中存在多个键值对,其中id是绝对不相同的,但其他键值对可能和另外的子元素重复,现在要去除重复的子元素
# 原始列表
original_list = [{"id": 1, "name": "Alice", "age": 20},{"id": 2, "name": "Bob", "age": 25},{"id": 3, "name": "Alice", "age": 30},{"id": 4, "name": "Carol", "age": 35},{"id": 5, "name": "Bob", "age": 25},
]# 辅助集合
seen = set()# 存储不重复子元素的列表
unique_list = []# 遍历原始列表
for item in original_list:# 创建子元素的唯一标识,不包含idunique_id = frozenset(item.items()) - frozenset([("id", item["id"])])# 如果唯一标识不在辅助集合中,表示非id部分是首次出现if unique_id not in seen:# 将唯一标识加入辅助集合中,用于判断后续是否重复出现seen.add(unique_id)# 将不重复的子元素添加到结果列表中unique_list.append(item)# 打印结果
print(unique_list)