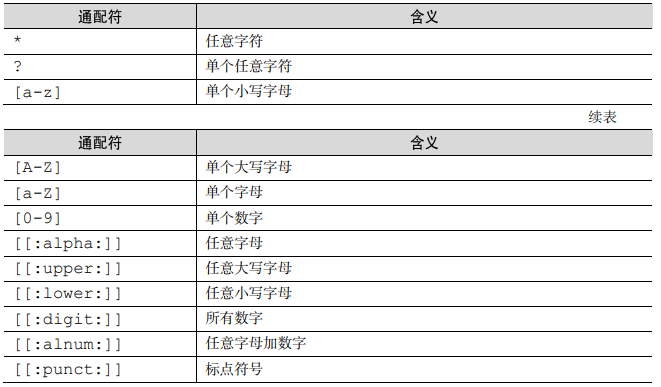
前言
前三次作业都是实现一个小型的答题判题程序,后一题都是在前一题的增加了特定的需求。
在这三次题目中,频繁的使用到了正则表达式,还使用到了map类,题量适中,在上一次的基础上进行迭代,难度也是一次比一次大,需求变得更加细致,对于程序健壮性要求更高,同时也要慢慢的考虑到类与类之间的关系。虽然感觉在这三次题目没怎么仔细考虑过类与类之间的关系,但在后续的作业中肯定对着方面有要求。
下面对三次作业的答题判题程序进行分析。
设计与分析
第一次答题判题作业
设计
这次作业的要求不是很复杂,题目的要求是:
输入题目数量n,接着输入n道题目,题目包括题号、题目内容和标准答案,最后输入答题信息,根据答题信息输出相应的结果。
因为是给定了题目的数量,所以使用数组来建立题目集合
根据题目给定的类提示进行设计,三个类:题目类、试卷类、答卷类
在主类里面对三个类对象进行初始化,这还是挺简单的
主要完成以下流程
1.解析输入信息
2.根据解析出的数据初始化对象,然后通过调用成员方法进一步初始化对象
3.输出结果
踩的坑:
输入信息的获取可以利用正则表达式进行匹配,第一次提交时,有两个测试点没过,经过漫长的试错,原来是正则表达式写错了
改正前的正则表达式:
String regex="#N:\s(\d+)\s#Q:\s(.+) \s#A:\s(.+)\s";
其中对于题目答案的获取存在一点小问题,题目内容的获取:#Q:\s(.+) \s
因为在默认情况下,正则表达式的匹配是贪婪的,会尽可能多的匹配符合要求的字符串,因此这样可能会导致匹配到多余的空格,因此要采用非贪婪模式
下面是一个模拟改正之前匹配的结果:
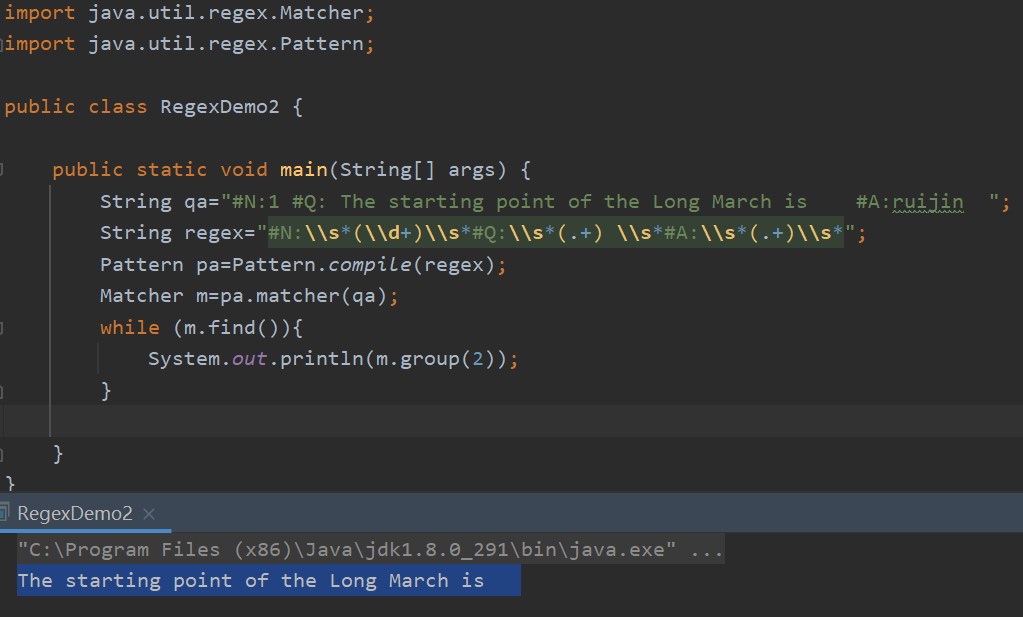
可见题目内容匹配了多余的空格
改成以后的正则表达式:
String regex="#N:\s(\d+)\s#Q:\s(.+?)\s#A:\s(.+)\s";
下面是一个模拟改正之后匹配的结果:
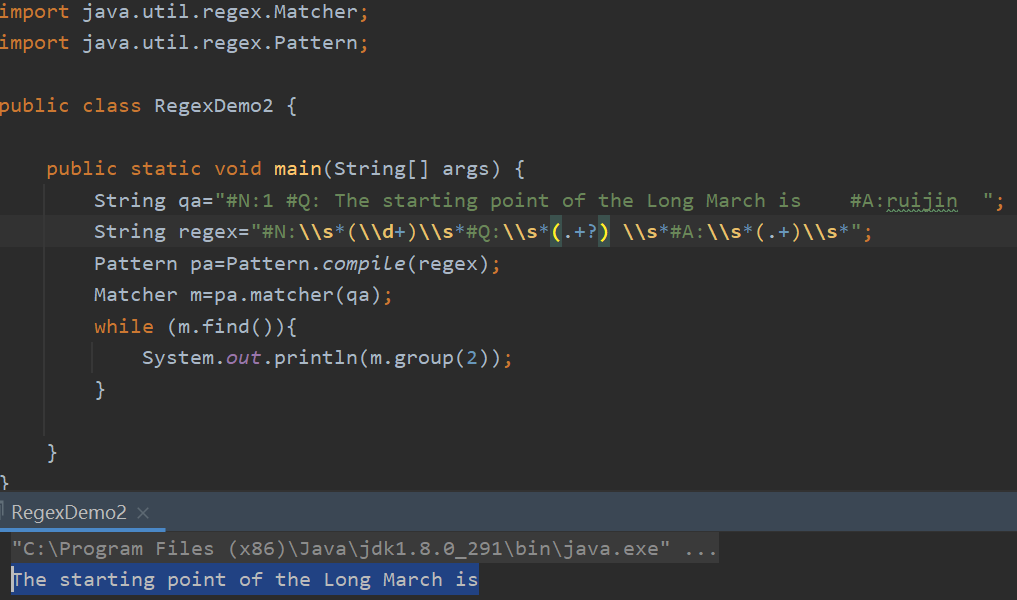
这样就正常了
不过对于以上的问题,有一种更好的解决方法,就是先不用考虑空格,捕获之后调用trim()方法去掉首尾空格,这也是我写到第三次题才后知后觉的方法
实现如下:
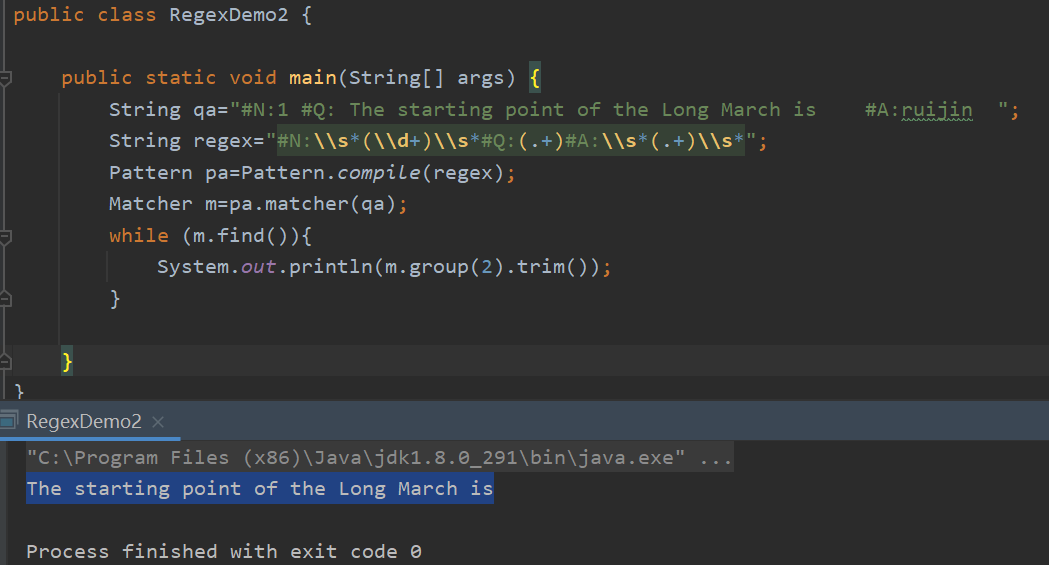
分析
类图和度量
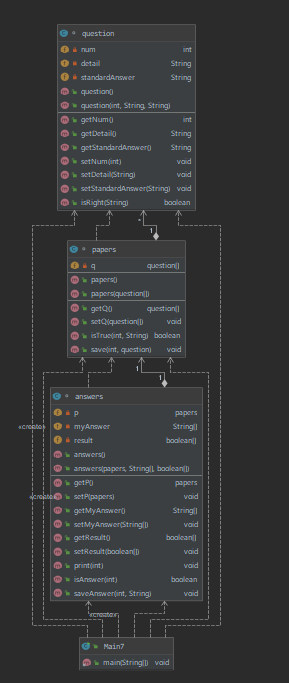
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
| answers | 1.3636363636363635 | 4.0 | 15.0 |
| Main7 | 8.0 | 8.0 | 8.0 |
| papers | 1.1666666666666667 | 2.0 | 7.0 |
| question | 1.1111111111111112 | 2.0 | 10.0 |
| Total | 40.0 | ||
| Average | 1.4814814814814814 | 4.0 | 10.0 |
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| answers.answers() | 0.0 | 1.0 | 1.0 | 1.0 |
| answers.answers(papers, String[], boolean[]) | 0.0 | 1.0 | 1.0 | 1.0 |
| answers.getMyAnswer() | 0.0 | 1.0 | 1.0 | 1.0 |
| answers.getP() | 0.0 | 1.0 | 1.0 | 1.0 |
| answers.getResult() | 0.0 | 1.0 | 1.0 | 1.0 |
| answers.saveAnswer(int, String) | 0.0 | 1.0 | 1.0 | 1.0 |
| answers.setMyAnswer(String[]) | 0.0 | 1.0 | 1.0 | 1.0 |
| answers.setP(papers) | 0.0 | 1.0 | 1.0 | 1.0 |
| answers.setResult(boolean[]) | 0.0 | 1.0 | 1.0 | 1.0 |
| papers.getQ() | 0.0 | 1.0 | 1.0 | 1.0 |
| papers.papers() | 0.0 | 1.0 | 1.0 | 1.0 |
| papers.papers(question[]) | 0.0 | 1.0 | 1.0 | 1.0 |
| papers.save(int, question) | 0.0 | 1.0 | 1.0 | 1.0 |
| papers.setQ(question[]) | 0.0 | 1.0 | 1.0 | 1.0 |
| question.getDetail() | 0.0 | 1.0 | 1.0 | 1.0 |
| question.getNum() | 0.0 | 1.0 | 1.0 | 1.0 |
| question.getStandardAnswer() | 0.0 | 1.0 | 1.0 | 1.0 |
| question.question() | 0.0 | 1.0 | 1.0 | 1.0 |
| question.question(int, String, String) | 0.0 | 1.0 | 1.0 | 1.0 |
| question.setDetail(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| question.setNum(int) | 0.0 | 1.0 | 1.0 | 1.0 |
| question.setStandardAnswer(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| answers.isAnswer(int) | 1.0 | 2.0 | 1.0 | 2.0 |
| papers.isTrue(int, String) | 1.0 | 2.0 | 1.0 | 2.0 |
| question.isRight(String) | 1.0 | 2.0 | 1.0 | 2.0 |
| answers.print(int) | 5.0 | 1.0 | 4.0 | 4.0 |
| Main7.main(String[]) | 9.0 | 1.0 | 7.0 | 8.0 |
| Total | 17.0 | 30.0 | 36.0 | 40.0 |
| Average | 0.6296296296296297 | 1.1111111111111112 | 1.3333333333333333 | 1.4814814814814814 |
主方法和打印输出方法复杂度较高,因为在它们方法体里面要实现多种方法的调用和判断等。
第二次答题判题作业
设计
这次在上一次的基础上加了输入试卷信息还有各种边界问题。由于不知道题目的个数,所以用TreeMap类存储题目的集合
设计三个类:问题类、试卷类、答卷类
基本流程不用多说,上面已经给出
与上次相比,输入的不确定性使得我多次出现空指针异常错误,为此设计了许多判断分支语句,因此代码显得非常难看,可维护性较低,在第三次作业才重写了有许多判断分支的方法,重写之后显得简单易懂。
踩的坑:
因为要采用map存储数据,所以最开始我使用了HashMap还有TreeMap类存储试卷的,但输出之后发现和试卷题目顺序对不上,调试之后才发现以这两这种类春出存储的数据似乎是按键的大小升序排序的,导致遍历并没有按照试卷上题目的输入顺序来,而是按照试卷上题号的顺序来。
改正:采用LinkedHashMap类存储试卷题目信息,这个类实现了预计效果,以为该类键值对在集合中的顺序是按照插入顺序进行排序的,这样就和试卷先出现的题目先输出对上了。
分析
类图和度量
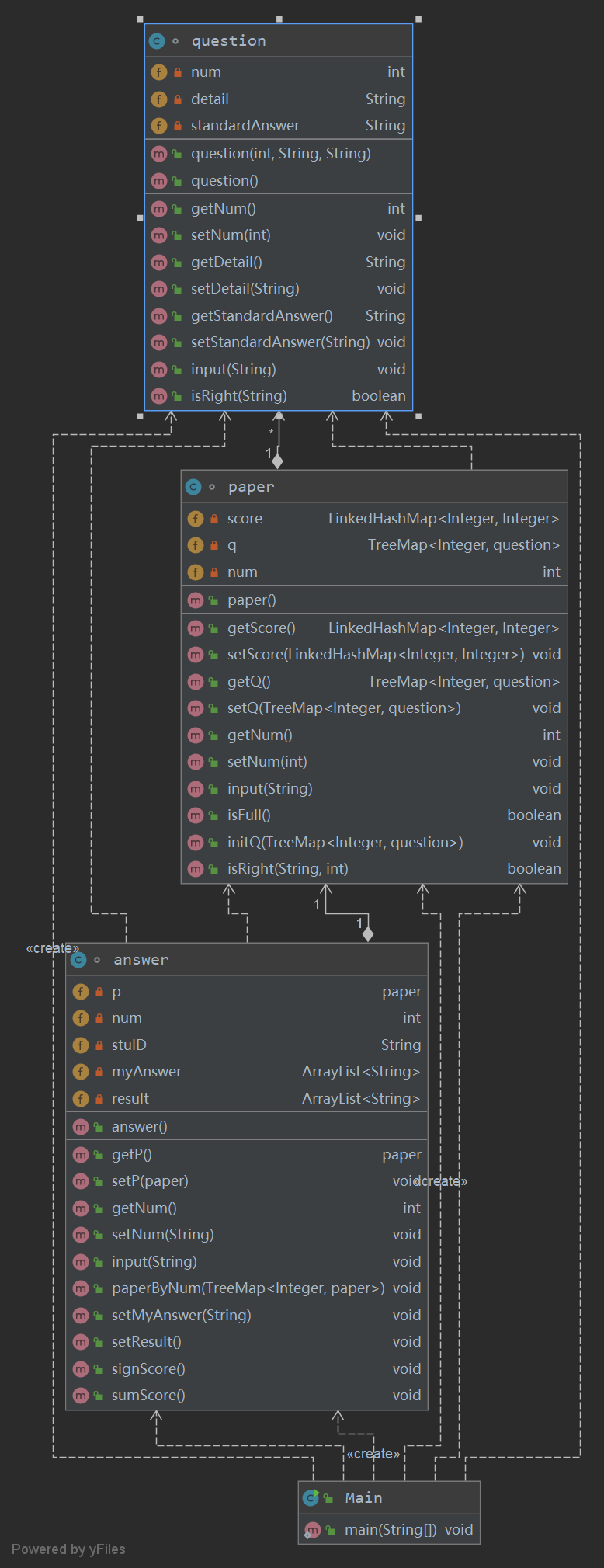
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
| question | 1.2 | 2.0 | 12.0 |
| paper | 1.4545454545454546 | 3.0 | 16.0 |
| answer | 2.5454545454545454 | 9.0 | 28.0 |
| Main | 12.0 | 12.0 | 12.0 |
| Total | 68.0 | ||
| Average | 2.0606060606060606 | 6.5 | 17.0 |
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| answer.answer() | 0.0 | 1.0 | 1.0 | 1.0 |
| answer.getNum() | 0.0 | 1.0 | 1.0 | 1.0 |
| answer.getP() | 0.0 | 1.0 | 1.0 | 1.0 |
| answer.input(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| answer.setP(paper) | 0.0 | 1.0 | 1.0 | 1.0 |
| paper.getNum() | 0.0 | 1.0 | 1.0 | 1.0 |
| paper.getQ() | 0.0 | 1.0 | 1.0 | 1.0 |
| paper.getScore() | 0.0 | 1.0 | 1.0 | 1.0 |
| paper.paper() | 0.0 | 1.0 | 1.0 | 1.0 |
| paper.setNum(int) | 0.0 | 1.0 | 1.0 | 1.0 |
| paper.setQ(TreeMap) | 0.0 | 1.0 | 1.0 | 1.0 |
| paper.setScore(LinkedHashMap) | 0.0 | 1.0 | 1.0 | 1.0 |
| question.getDetail() | 0.0 | 1.0 | 1.0 | 1.0 |
| question.getNum() | 0.0 | 1.0 | 1.0 | 1.0 |
| question.getStandardAnswer() | 0.0 | 1.0 | 1.0 | 1.0 |
| question.question() | 0.0 | 1.0 | 1.0 | 1.0 |
| question.question(int, String, String) | 0.0 | 1.0 | 1.0 | 1.0 |
| question.setDetail(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| question.setNum(int) | 0.0 | 1.0 | 1.0 | 1.0 |
| question.setStandardAnswer(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| answer.paperByNum(TreeMap) | 1.0 | 1.0 | 1.0 | 2.0 |
| answer.setMyAnswer(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| answer.setNum(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| paper.initQ(TreeMap) | 1.0 | 1.0 | 2.0 | 2.0 |
| paper.isFull() | 1.0 | 1.0 | 1.0 | 2.0 |
| paper.isRight(String, int) | 1.0 | 2.0 | 1.0 | 2.0 |
| question.input(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| question.isRight(String) | 1.0 | 2.0 | 1.0 | 2.0 |
| paper.input(String) | 2.0 | 1.0 | 3.0 | 3.0 |
| answer.signScore() | 4.0 | 1.0 | 3.0 | 3.0 |
| answer.setResult() | 7.0 | 4.0 | 3.0 | 5.0 |
| Main.main(String[]) | 16.0 | 3.0 | 11.0 | 12.0 |
| answer.sumScore() | 27.0 | 1.0 | 7.0 | 9.0 |
| Total | 64.0 | 40.0 | 59.0 | 68.0 |
| Average | 1.9393939393939394 | 1.2121212121212122 | 1.7878787878787878 | 2.0606060606060606 |
依旧是主方法和与输出有关的方法复杂度较高,这也可以理解,输出要进行多种判断和方法的调用,而主方法要实现输入信息解析,对象初始化,调用方法进行输出,因此复杂度高。
第三次答题判题作业
设计
本次在前一题的基础上又加上了删除题目信息,要求又进一步升级,加上了一个删除信息,可以在主类里面定义一个被删除题目题号的集合,给问题类增加一个数据域isDelete用来判断该题目是否被删除,将主类里面的被删除题目题号的集合作为参数传给相应的对象,然后将被删除的题目进行标记,进行输出时判断一下就行了。
本题依旧沿用第二次作业所设计的类。
主函数实现的流程也不过多解释。
这次没有在规定时间内完成所有测试点的通过,于是重写了一下,不过还是有五个测试点没过,估计还是和正则表达式没写好有关,不过在上一次的基础上,对输出结果的方法进行了改进简化,这一点我还是觉得很好的,毕竟没以前那么难懂了,这让我深刻体会到有一个合理的逻辑去写代码是多么重要。而不是为了得到结果不断在原有的难懂的代码上还去加更多的判断。
改进:
把遍历答卷答案改成遍历试卷题目信息,这样就不用考虑使用多种分支语句了。
分析
类图和度量
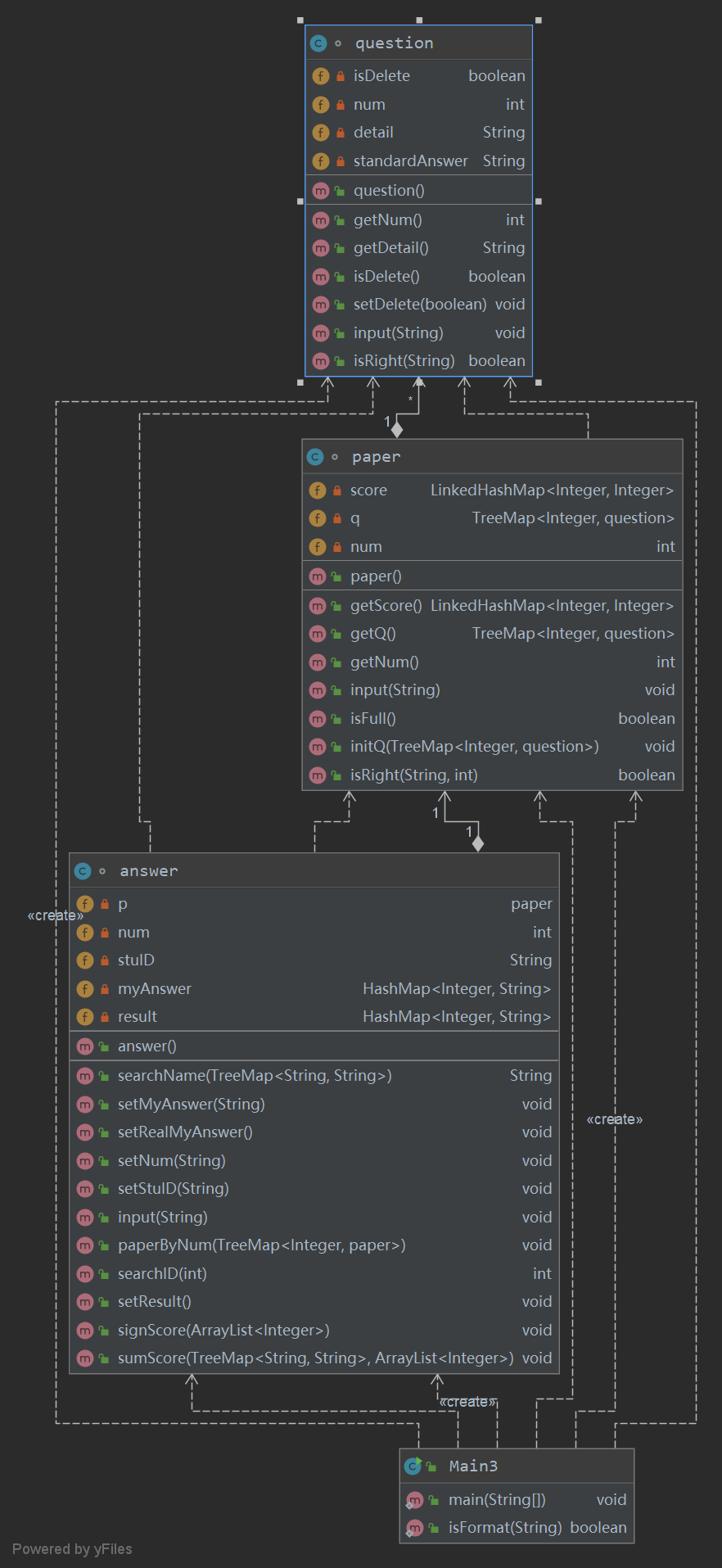
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
| question | 1.1428571428571428 | 2.0 | 8.0 |
| paper | 1.5 | 3.0 | 12.0 |
| answer | 3.25 | 7.0 | 39.0 |
| Main3 | 15.0 | 19.0 | 30.0 |
| Total | 89.0 | ||
| Average | 3.0689655172413794 | 7.75 | 22.25 |
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| answer.answer() | 0.0 | 1.0 | 1.0 | 1.0 |
| answer.input(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| paper.getNum() | 0.0 | 1.0 | 1.0 | 1.0 |
| paper.getQ() | 0.0 | 1.0 | 1.0 | 1.0 |
| paper.getScore() | 0.0 | 1.0 | 1.0 | 1.0 |
| paper.isRight(String, int) | 0.0 | 1.0 | 1.0 | 1.0 |
| paper.paper() | 0.0 | 1.0 | 1.0 | 1.0 |
| question.getDetail() | 0.0 | 1.0 | 1.0 | 1.0 |
| question.getNum() | 0.0 | 1.0 | 1.0 | 1.0 |
| question.isDelete() | 0.0 | 1.0 | 1.0 | 1.0 |
| question.isRight(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| question.question() | 0.0 | 1.0 | 1.0 | 1.0 |
| question.setDelete(boolean) | 0.0 | 1.0 | 1.0 | 1.0 |
| answer.paperByNum(TreeMap) | 1.0 | 1.0 | 1.0 | 2.0 |
| answer.searchName(TreeMap) | 1.0 | 2.0 | 2.0 | 2.0 |
| answer.setMyAnswer(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| answer.setNum(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| answer.setStuID(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| paper.initQ(TreeMap) | 1.0 | 1.0 | 2.0 | 2.0 |
| paper.isFull() | 1.0 | 1.0 | 1.0 | 2.0 |
| question.input(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| paper.input(String) | 2.0 | 1.0 | 3.0 | 3.0 |
| answer.searchID(int) | 3.0 | 3.0 | 3.0 | 3.0 |
| answer.setRealMyAnswer() | 4.0 | 2.0 | 3.0 | 4.0 |
| answer.sumScore(TreeMap, ArrayList) | 9.0 | 3.0 | 8.0 | 8.0 |
| answer.setResult() | 10.0 | 6.0 | 3.0 | 7.0 |
| answer.signScore(ArrayList) | 10.0 | 2.0 | 8.0 | 9.0 |
| Main3.isFormat(String) | 15.0 | 11.0 | 6.0 | 11.0 |
| Main3.main(String[]) | 43.0 | 1.0 | 19.0 | 19.0 |
| Total | 104.0 | 51.0 | 80.0 | 93.0 |
| Average | 3.586206896551724 | 1.7586206896551724 | 2.7586206896551726 | 3.206896551724138 |
这次比前两次都复杂,因为考虑的情况多了,复杂了也挺正常,判断格式和输出结果的方法复杂度注定很高。
学到了什么
了解了正则表达式在解析特定格式字符串的强大之处,同时使用正则表达式也要注意很多,例如贪婪和非贪婪,分组匹配等。学到了类的基本使用,同时初步了解了map类的一些知识,例如HashMap、LinkedHashMap和TreeMap,LinkedHashMap的键值对的遍历是按照插入顺序来遍历的,等等。同时体会了逻辑清晰的代码阅读起来是多么舒服,以后一定先把逻辑想好在开始写代码。
在这个过程中,我感觉只是初步了解面向对象思想,并没有深刻体会,在三次题目中也没有把握这种思想,这是我要慢慢去领会的