指令优化:基于大型语言模型的指令算子的进化多目标指令优化
摘要
基于指令的语言建模在预训练的语言模型中受到了极大的关注。
提出了一种指令优化方法,将指令生成视为一个进化的多目标优化问题,利用大型语言模型(LLM)来模拟指令运算符,包括变异和交叉。
此外,为这些运算符引入了一种目标导向机制,使LLM能够理解目标并提高生成指令的质量。实验结果表明,ffne调优性能得到了提高,并生成了一组不同的高质量指令。
1简介
随着语言模型的快速发展,指令在语言建模中发挥着至关重要的作用,不同的指令可能导致模型输出的显著差异。例如,即使是轻微扰动的指令(例如,同义词替换或对抗性攻击),也会导致出乎意料的低性能。
首先,现有的工作旨在通过自动指令生成获得大量指令,以生成高性能指令。
然而,由于文本搜索空间大且不可微分,自动化指令生成和指令工程方法无效,难以搜索各种高质量指令。
其次,指令生成的目标并不明确。目前的研究将绩效(即指标)视为教学质量的唯一标准。然而,仅凭模型性能并不能准确地解释教学质量。
建议通过考虑模糊粒度的目标,如长度和困惑来重新定义教学质量。更短的指令可以降低计算成本,尤其是对于大型模型和数据集。较低的困惑度表明指令更容易被语言模型理解。
最后,在现有的研究中,指令的多样性被忽视了,而增加指令的多样度可以减轻对抗性攻击并提高指令的鲁棒性。目标是基于多目标优化获得多个备选指令,这有助于对指令进行综合评估。
为了解决这三个问题,将任务定义为一个进化的多目标优化问题,并提出了框架指令优化。利用一个大型语言模型,特别是ChatGPT,来促进突变和交叉等指令操作。此外,引入了一种客观引导机制来帮助语言模型生成高质量的指令。
在指令生成的优化目标方面,指令优化包含了三个目标:性能(指标)、长度和困惑,从而能够探索多样化和高质量的指令集。在指令优化中采用NSGA-II来获得指令集的Pareto前沿。
为了验证指令优化的有效性,在三个基于生成的分类任务上进行了实验。实验结果表明,指令优化可以同时获得一组在性能方面优于同行的不同指令。
总之,贡献如下:
•模拟基于LLM的指令运算符,,目标导向算子有助于LLM理解优化目标值。
•将指令搜索的方向划分为多个目标,如性能、长度和困惑,便于对指令质量进行细粒度控制。
•利用多目标优化算法自动搜索一组高质量指令,这有助于抵御对抗性攻击,提高指令鲁棒性。
代码位于:https://github.com/yangheng95/指令优化.
2建议方法
在本节中,首先介绍基于指令的文本生成,然后介绍指令优化的详细信息。
2.1基于指令的生成
在基于文本生成的任务1中,指令用于促进上下文学习并改进语言建模。指令(如图1的右部分所示)表示为

,其中
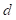
和

分别是目标任务的定义和示例。
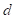
和是
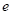
类似于
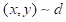
的标记序列,其中

,
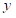
和分

别表示输入、输出和任务数据集。一个生成模型
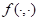
的建模定义如下:

(9-7-1)
其中,
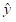
表示给定

和
的生成输出。在指令优化中,目标是通过多目标优化来解决自动指令生成的问题。
2.2进化指令优化
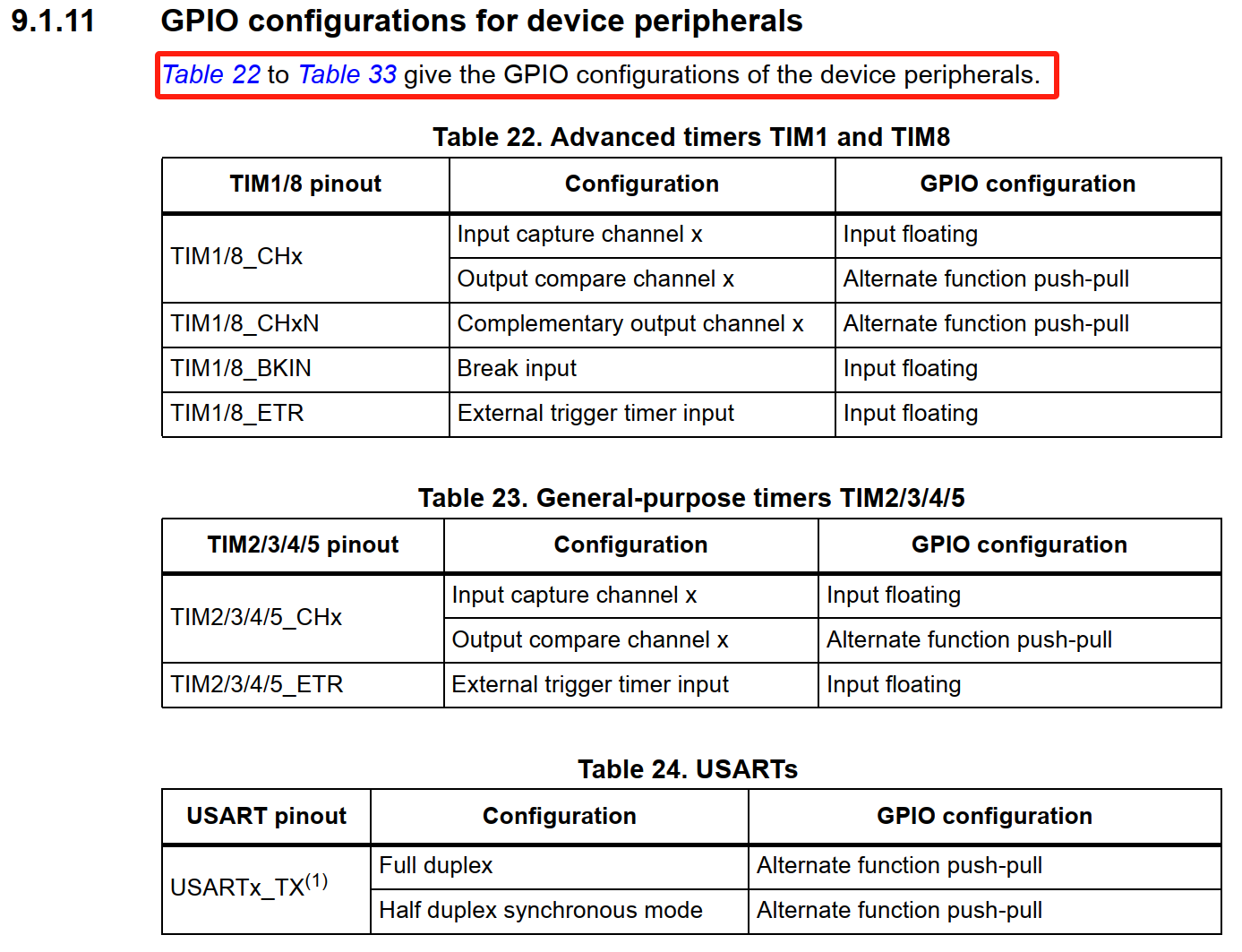
指令优化的工作流程如图1所示。从初始化指令的父种群开始进化。通过基于LLM的算子对父种群进行操作以生成子种群。随后,使用非支配排序算法对组合种群进行排序,并测量指令的拥挤度。
在每一代结束时,用新的指令随机替换一些Pareto前沿指令,以增强群体的多样性(在NSGA-II中称为基因)。还在附录A.4中提供了指令优化的伪代码。
2.2.1操作员须知
为了处理不可微的文本搜索空间,将这些运算符公式化为基于ChatGPT的文本生成任务。换句话说,定义了一组ffxed提示

,

,以指导ChatGPT执行指令,其中
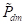
、

、

、
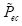
是四个操作的模糊提示:
•定义突变(
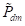
)
:此运算符使指令中的定义发生突变。它可以包括对新定义的转述和替换。
•定义交叉(
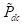
):
此运算符将两条指令的定义组合起来创建一条新指令。它可能涉及在父指令之间合并或交换部分定义。
•示例突变(

):此运算符扰乱示例以引入多样性。它可以
涉及修改,例如替换、添加或删除。
•示例交叉(

):此运算符从两条指令中随机选择示例以创建新指令。
例如,将突变操作公式化如下:
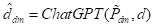
(9-7-2)
其中是基于原始指令生成的新定义。新指令表示为
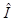
,

。其他操作符遵循与突变相似的公式。
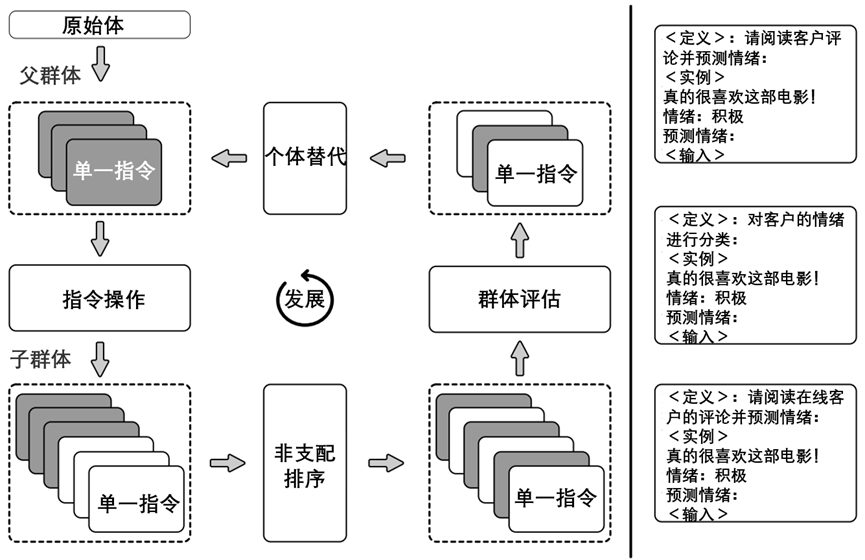
图9-7-1. 指令优化的主要框架(左)和指令操作示例(右)。第2.2节中解释了工作流的详细信息。群体由教学实例的个体组成。
2.2.2优化目标
在优化中,考虑三个目标,即指令的度量(
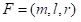
)、长度(
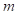
)和困惑(

)。
•绩效:使用一组指标,如准确度、
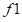
分数、准确度和召回率,通过评估指令来计算绩效目标。性能目标表示为这些指标之和的倒数。
•长度:指令的长度是根据字符数来衡量的。无论标记化策略如何,这种衡量都是公平的。
•困惑:使用RoBERTa模型测量教学的困惑。
目标

的评估如附录A.4中的伪代码所示,但为了简单起见,图9-7-1中没有描述。
2.3目标导向的指导操作员
为了通过上下文学习提高ChatGPT的性能,提出了一种简单而有效的客观反馈机制。具体来说,将拟合值合并到固定的提示中。例如,在指令示例交叉中,可以将“请参考目标值:
,

”附加到。
这些运 算符允许ChatGPT
基于当前目标自主决定强调或减轻指令的权重。
3实验设置
使用随机指令(RanInstruction)生成(即,请求ChatGPT生成几个类似于指令优化生成的指令的指令)和无指令(NoInstruction,无指令)作为比较基线。
随机指令使用LLM生成ffve随机指令,以评估与指令优化相同的三个目标。
无指令在Flan-T5的面向分类的ffne调谐中提供指导。
表1:指令优化的实验性能。为了直观的评估,展示了准确性而不是性能目标。符号的↗ 和↘分别表示越大越好和越低越好。在ffve轮中重复每个实验,并报告平均结果。最佳结果以粗体显示。精度是Pareto-front的最佳精度,而长度和困惑度与实现最佳精度的指令相关。

3.2主要结果
表1中的结果显示了指令优化的性能。总体而言,指令优化实现了基于各种基础模型(例如ChatGPT和FlanT5)的卓越目标。例如,它在精度方面优于所有数据集上的所有基线。然而,对于指令长度和困惑度,随机指令有时会达到更好的目标值。另一方面,无指令在所有数据集上的准确性都很差,这突出了指令在基于生成的偏移中的重要性。
此外,精度目标显示出较小的间隔但相对较大的方差,这使得优化更具挑战性。然而,现有的优先考虑性能优化的方法很难处理指标中的差异。
另一方面,LENGTH目标更容易优化,因为它的显著变化更大。这是因为长指令的训练时间可能是短指令的两倍。困惑度度量的范围很小,表明存在适度的优化挑战,但它会显著影响指导工程师的理解。除了这三个目标之外,指令优化还可以轻松地容纳额外的目标,以精确控制指令生成。
总的来说,指令优化在各种任务和数据集的指令优化方面表现出了令人印象深刻的性能。
3.3研究问题
通过回答几个研究问题来进一步讨论观察和分析。
表2:指令优化-N在FlanT5上的实验性能很小。标记“−”和“+”表示比指令优化更差和更好的目标。

为了研究目标引导操作员对指令优化的影响,进行了消融实验来评估指令优化-N的性能,这消除了操作员的目标引导。表2中给出了FlanT5-small的实验结果。
根据表1和表2中的结果,很明显,指令优化-N在大多数数据集上实现了较差的目标值,特别是在精度和长度方面。然而,对于SNLI数据集,与指令优化相比,指令优化-N在准确性和困惑度方面获得了更好的结果。这些发现证明了有效性目标导向操作员。尽管如此,目标导向算子的概念仍处于早期阶段,值得在未来的研究中进一步研究。
总之,实验结果表明,目标引导算子在各种数据集上都能获得更好的性能。
RQ2:进化世代的数量在指令优化中重要吗?
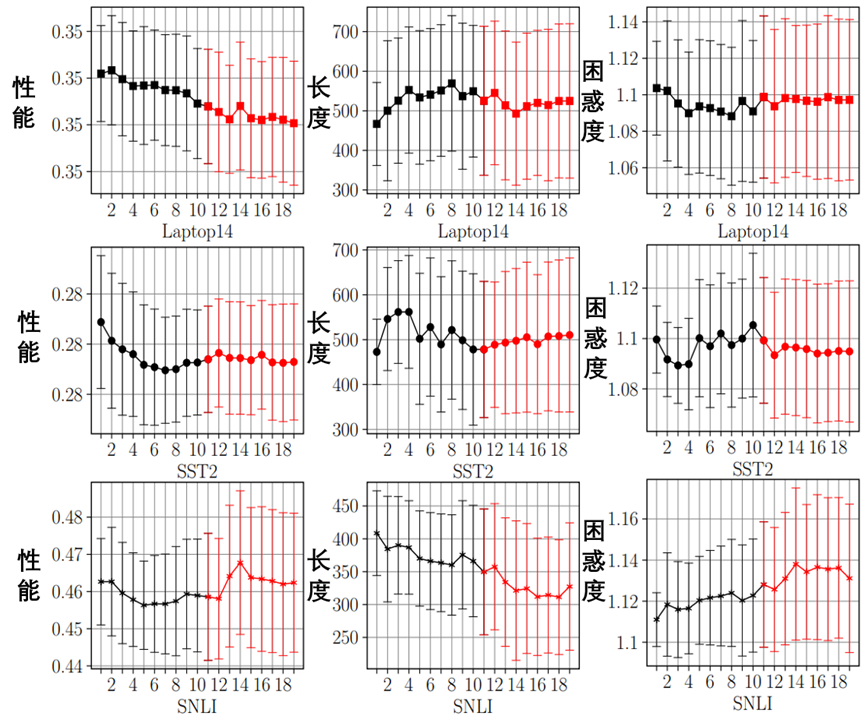
图2:不同数据集的目标值轨迹图。用红线绘制了另外10代人的轨迹。在这些图中,较低的目标值表示更好的性能。
通常,在优化后,更大数量的代往往会产生更好的目标值。
在Laptop14、SST2和SNLI数据集上对10代进行了额外的训练,以研究代数的意义。基于图中的实验结果。在大多数情况下(例如,Laptop14和SNLI数据集),观察到三个目标之间存在显著的权衡。然而,由于评估数据的规模和总体规模较小,绩效目标存在较大差异(见图2中的左列)。这些表现上的差异干扰了其他两个目标的趋同,导致随着世代的增加,长度和困惑目标没有明显的下降趋势。
然而,这个问题可以通过增加人口规模、世代数量和训练数据的规模来解决。
总之,在评估资源有限的情况下,进化代的数量改善有限。相反,重要的是要调和不同的目标值,以实现最终的教学群体。
不同目标之间是否存在权衡?
为了分析不同目标之间的关系,将指令的Pareto前沿(见图5)划分为三组。成对目标之间的二维Pareto前沿,如图3所示。
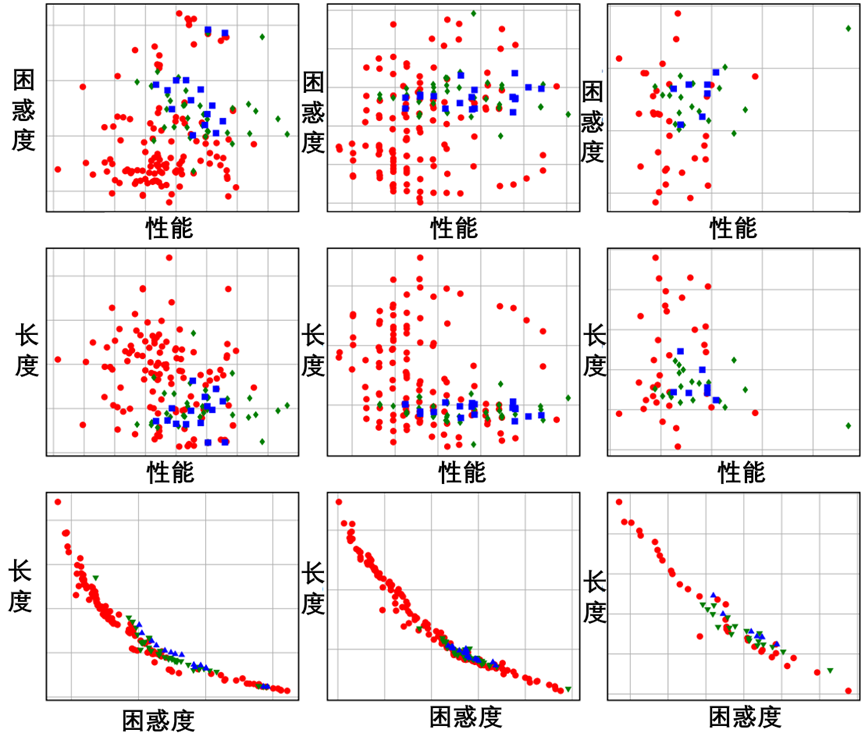
图3:指令优化在三个数据集上搜索的2D Pareto前沿的可视化。从左到右的三列分别表示Laptop14、SST2和SNLI数据集上的结果。
总的来说,在指令长度和困惑之间存在着明显的权衡。然而,当考虑到性能长度和性能困惑的配对时,在图中没有观察到明显的权衡。这可能是由于在优化过程中对小数据集上的度量进行评估,导致缺乏严格的权衡,并且存在噪声模糊点。预计在较大数据集上评估性能时,可以缓解此问题。
尽管如此,指令优化在大多数情况下都能始终如一地发现高质量的指令,而不考虑性能长度和性能困惑等目标对之间的松散权衡。
这证明了指令优化在获得不同指令集方面的有效性。
5限制
指令优化的第一个局限性在于多目标优化中局部最优的潜在危机。指令优化基于ffxed手动编制的指令初始化指令填充,然后使用LLM对这些指令进行变异。
尽管指令优化已经在实验中被证明可以搜索多样化和高质量的指令,但在多目标过程中,模糊初始指令的本质可能会导致局部最优的陷阱。在未来,初始指令群体的生成,例如使用随机初始指令,仍然是一个值得探索的话题。
指令优化的第二个局限性与实验资源有关。由于资源限制,只使用单轮API调用来使用LLM生成新指令。这种方法忽略了上下文信息,这些信息可能有助于理解教学生成中的客观反馈。相信,与LLM的持续对话将显著提高LLM产生的教学质量。此外,由于访问LLM的困难,进行了较小种群规模和较少迭代的实验,这可能低估了指令优化的性能。
参考文献链接
InstOptima: Evolutionary Multi-objective Instruction Optimization via Large Language Model-based Instruction Operators