MLIR多层中间表示——用MLIR构建编译器(上)
1.1. MLIR概述
本文旨在介绍MLIR,不需要事先了解,但有时会将其与LLVM进行比较,因此具有LLVM的经验可能会使其更容易遵循。
将从MLIR的高级介绍开始,然后再深入了解一些内部内容,以及这些内容如何应用于示例用例。
概述
通过实现一种基本的玩具语言的方式参观MLIR(经过许多简化)
● 定义玩具语言
● MLIR核心概念:业务、地区、方言
● 使用MLIR表示玩具
○ 介绍方言、操作、ODS、验证
○ 将语义附加到自定义操作
● 高级语言特定优化
● 为结构而非操作编写通行证
○ 获胜的操作界面
● 降为低级方言
○ LLVM IR之路
以下是本教程的概述:
● 将制作一个非常简化的基于高级阵列的DSL:这是一种专门用于本教程的Toy语言。
● 然后,介绍了MLIR IR中的一些关键核心概念:操作、区域和方言。
● 然后将这些概念应用于设计和构建承载语言语义的IR。
● 展示了其他MLIR概念,如接口,并解释了框架如何组合在一起以实现转换。
● 将把代码降低到更适合CodeGen的表示形式。
MLIR中的方言概念允许逐步降低并引入面向特定领域优化的特定领域的中端表示。对于CPU CodeGen,LLVM当然是王道,但也可以实现不同的降低,以针对自定义加速器或FPGA。
什么是MLIR?
● 构建编译器IR的框架:定义类型系统、操作等。
● 涵盖编译器基础架构需求的工具箱
○ 诊断、传递基础设施、多线程、测试工具等。
● 动力包括:
○ 各种代码生成/降低策略
○ 加速器支持(GPU)
● 允许不同级别的抽象自由共存
○ 摘要可以更好地针对特定领域,减少高级信息的丢失
○ 渐进式降低简化并增强了转换管道
○ 没有任意的抽象边界,例如主机和设备代码同时位于同一IR中
什么是MLIR?在深入细节之前,先从高层开始。
MLIR是一个用于构建和集成编译器抽象的工具箱,但这意味着什么?从本质上讲,目标是为编译器基础设施需求提供可扩展和易于使用的基础设施。可以定义自己的操作集(或LLVM中的指令)、自己的类型系统,并从过程管理、诊断、多线程、序列化/反序列化以及可能必须自己构建的所有其他无聊的基础设施中获益。
MLIR项目也是包含动力的:在通用基础设施之上,集成了多个抽象和代码转换。该项目还很年轻,但目标是推出各种代码生成策略,这些策略将允许轻松地重用端到端流,以将异构计算(例如以GPU为目标)包括到DSL或环境中!
多级方面在MLIR中非常重要:添加新的抽象级别旨在变得简单和常见。这不仅使对特定领域进行建模变得非常方便,还开辟了大量的创造力,并为编译器提供了大量的自由度来进行各种设计:这实际上非常有趣!
示例:
● 通用语言的高级IR:FIR(Flang IR)
● “ML图形”:TensorFlow/ONNX/XLA/…。
● 硬件设计:CIRCT项目
● 运行时间:TFRT、IREE
● 研究项目:Verona(并发),RISE(功能)…
MLIR允许各种抽象自由共存。这是心态中非常重要的一部分。这使得抽象能够更好地针对特定领域;例如,人们一直在使用MLIR为Fortran、机器学习图(张量级运算、量化、跨主机分布)、硬件合成、运行时抽象、研究项目(例如,围绕并发)构建抽象。
甚至有用MLIR优化MLIR的DAG重写的抽象。因此,使用MLIR来优化MLIR。如果有兴趣了解更多关于这些MLIR用户的信息,网站上会引用这些用户。
1.2. 通过创建引入MLIR:一种玩具语言
在本教程中,将介绍一种玩具语言,以突出MLIR的一些重要方面。
让构建一种玩具语言
● 标量和数组计算以及I/O的混合
● 阵列形状推断
● 泛型函数
● 一组非常有限的运算符和功能(这只是一种玩具语言!)

这种高级语言将说明MLIR如何为编程语言的高级表示提供便利。将使用一种语言,因为它对许多人来说是一种熟悉的流程,但这里的概念适用于语言之外的许多领域(只看到了一些实际用例的例子!)
现有的成功编译模型

一种传统的编译模型:AST->LLVM
最近的编译器添加了额外级别的特定于语言的IR,将AST模型细化为LLVM,并在不同的表示形式之间逐渐降低。为Toy挑选什么?想要尽可能现代化和经得起未来考验的东西。

应该遵循叮当模式吗?在到达LLVM之前,有一些高级任务要执行。
需要一个复杂的AST,用于转换和分析的重型基础设施,AST表示对此并不适用。
Toy编译器:具有特定语言的优化

要进行更多优化:需要自定义IR
重新实现LLVM的所有基础设施?
对于特定于语言的优化,可以使用内置和自定义LLVM通行证,但最终可能会希望IR处于正确的水平。这确保了以一种方便分析/转换的方式获得语言的所有高级信息,否则当降低到不同的表示形式时可能会获得这些信息。
异构编译器

在某种程度上,甚至可能想将程序的某些部分卸载到自定义加速器,这需要在IR中表示更多的概念。
这都是关于方言的!
MLIR允许每一个抽象级别都被建模为方言。

在MLIR中,抽象的关键组成部分是方言。
根据预算调整目标
对于Toy IR,只能使用一种方言:仍然足够灵活,可以执行形状推理和一些高级优化。

为了简单起见,将采取许多快捷方式并尽可能简化流程,以将自己限制在获得端到端示例所需的最小值。还将把异构部分留给将来的会议。
MLIR入门
在进入玩具之前,先介绍一下MLIR中的一些关键概念。
操作,而非说明
● 没有预定义的指令集
● 对MLIR来说,操作就像不透明的功能

在MLIR中,一切都是关于操作的,而不是指令:强调要与LLVM视图区分开来。操作可以是粗粒度的(执行矩阵乘法,或启动远程RPC任务),也可以直接携带循环嵌套或其他类型的嵌套“区域”(请参阅后面的幻灯片)。
递归嵌套:操作->区域->块

● 区域是嵌套在操作内部的基本块的列表。
○ 基本块是一个操作列表:IR结构是递归嵌套的!
● 概念上类似于函数调用,但可以引用外部定义的SSA值。
● 内部定义的SSA值不会转义。
操作的另一个重要特性是它可以容纳区域,这是代码的任意大嵌套部分。
区域是基本块的列表,这些块本身就是操作的列表:结构是递归嵌套的!
操作->区域->块->操作->…是IR的基础:所有东西都适合这个嵌套:甚至ModuleOp和FuncOp都是常规操作!
例如,函数体是附加到FuncOp的唯一区域。
不会大量使用区域,但它们在MLIR中是常见的,并且在表达IR的结构方面非常强大,将在几张幻灯片中以一个例子回到这一点。
The “Catch”
func @main() {
%0 = "toy.print"() : () -> tensor<10xi1>
}
但是这是无效的!在许多方面都不完善:
● toy.int内建函数不是终结符;
● 应该取一个操作数;
● 不应该产生任何结果。
编译器IR的JSON?
MLIR是灵活的,它只受上一张幻灯片中介绍的结构的限制!
然而,这是否过于灵活?
可以很容易地对像这里这样没有任何意义的IR进行建模。
刚刚创建了编译器IR的JSON吗?
方言:为IR定义规则和语义
MLIR方言是一个逻辑分组,包括:
● 前缀(“名称空间”保留)
● 自定义类型的列表,每个类型都有自己的C++类。
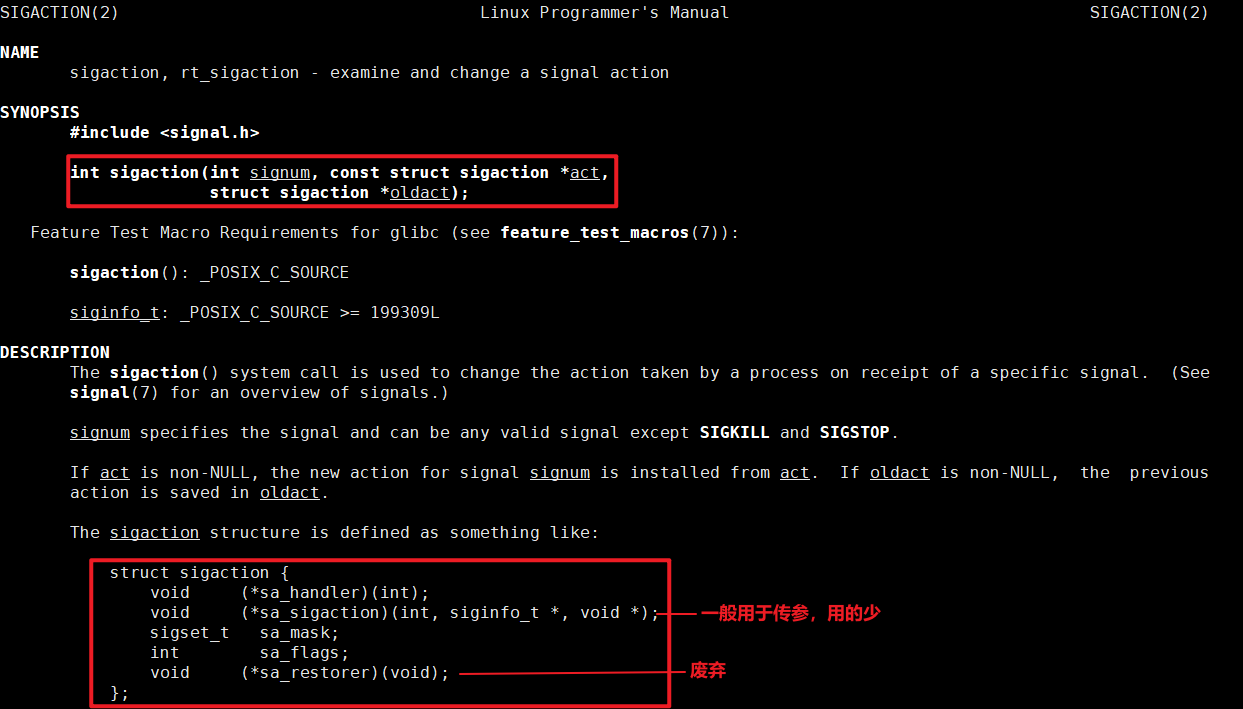
● 操作列表,每个操作的名称和C++类实现:
○ 操作不变量的验证器(例如toy.print必须有一个操作数)
○ 语义(没有副作用,不断折叠,允许CSE,……)
● 通过:分析、转换和方言转换。
● 可能是自定义解析器和汇编输出。
MLIR提出的解决方案是方言。
会在MLIR生态系统中听到很多关于“方言”的信息。方言有点像C++库:它至少是一个命名空间、一组类型、一组操作这些类型(或其他方言定义的类型)的操作。
方言加载在MLIRContext中,并提供各种挂钩,例如IR验证器:它将在IR上强制执行不变量(就像LLVM验证器一样)。
方言作者还可以自定义操作和类型的打印/解析,使IR更具可读性。
方言是廉价的抽象:创建一个方言就像创建一个新的C++库一样。MLIR捆绑了20种方言,但更多的方言是由MLIR用户定义的:到目前为止,在谷歌的内部用户已经定义了60多种!
例:仿射方言

使用附加到操作的区域的良好语法*和高级语义的示例
在使用MLIR时,请记住自定义解析器/打印机是“易读的”,但可以始终打印IR的通用形式(在命令行上:--MLIR-print-op-generic),它实际上同构于内存中的表示。它有助于调试或理解如何在C++中操作IR。
例如,affine.For循环非常漂亮且可读,但泛型形式确实显示了实际的实现。
LLVM作为方言
%13 = llvm.alloca %arg0 x !llvm.double : (!llvm.i32) -> !llvm.ptr<double>
%14 = llvm.getelementptr %13[%arg0, %arg0]
: (!llvm.ptr<double>, !llvm.i32, !llvm.i32) -> !llvm.ptr<double>
%15 = llvm.load %14 : !llvm.ptr<double>
llvm.store %15, %13 : !llvm.ptr<double>
%16 = llvm.bitcast %13 : !llvm.ptr<double> to !llvm.ptr<i64>
%17 = llvm.call @foo(%arg0) : (!llvm.i32) -> !llvm.struct<(i32, double, i32)>
%18 = llvm.extractvalue %17[0] : !llvm.struct<(i32, double, i32)>
%19 = llvm.insertvalue %18, %17[2] : !llvm.struct<(i32, double, i32)>
%20 = llvm.constant(@foo : (!llvm.i32) -> !llvm.struct<(i32, double, i32)>) :
!llvm.ptr<func<struct<i32, double, i32> (i32)>>
%21 = llvm.call %20(%arg0) : (!llvm.i32) -> !llvm.struct<(i32, double, i32)>
LLVM IR本身可以建模为方言,并且实际上是在MLIR中实现的!
会发现LLVM指令和类型,前缀为“LLVM”方言命名空间。
LLVM方言的功能并不完整,但它定义了足够多的LLVM来支持面向DSL的代码生成的共同需求。
与LLVM IR也有一些微小的偏差:例如,由于MLIR结构的原因,常数并不特殊,而是被建模为常规运算。
参考文献链接
https://llvm.org/devmtg/2020-09/slides/MLIR_Tutorial.pdf