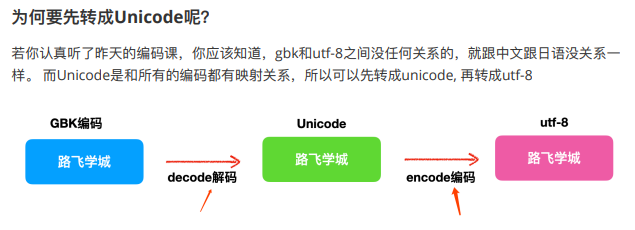
sysbench的部分基准性能测试学习
命令
Compiled-in tests:fileio - File I/O testcpu - CPU performance testmemory - Memory functions speed testthreads - Threads subsystem performance testmutex - Mutex performance test通用参数
General options:--threads=N number of threads to use [1]--events=N limit for total number of events [0]--time=N limit for total execution time in seconds [10]--warmup-time=N execute events for this many seconds with statistics disabled before the actual benchmark run with statistics enabled [0]--forced-shutdown=STRING number of seconds to wait after the --time limit before forcing shutdown, or 'off' to disable [off]--thread-stack-size=SIZE size of stack per thread [64K]--thread-init-timeout=N wait time in seconds for worker threads to initialize [30]--rate=N average transactions rate. 0 for unlimited rate [0]--report-interval=N periodically report intermediate statistics with a specified interval in seconds. 0 disables intermediate reports [0]--report-checkpoints=[LIST,...] dump full statistics and reset all counters at specified points in time. The argument is a list of comma-separated values representing the amount of time in seconds elapsed from start of test when report checkpoint(s) must be performed. Report checkpoints are off by default. []--debug[=on|off] print more debugging info [off]--validate[=on|off] perform validation checks where possible [off]--help[=on|off] print help and exit [off]--version[=on|off] print version and exit [off]--config-file=FILENAME File containing command line options--luajit-cmd=STRING perform LuaJIT control command. This option is equivalent to 'luajit -j'. See LuaJIT documentation for more information
测试CPU
--cpu-max-prime=Nsysbench的CPU测试是在指定时间内,
进行多轮次的素数计算。
除了1和它自身外,不能被其他自然数整除的数叫做素数(质数)。
一次event代表一轮的素数计算,即算出*–cpu-max-prime*以内的所有素数。能获得的测量指标:每秒完成的events数
N%events的耗时范围。例:95%的events耗时在0.5ms以内
总耗时
完成的events总数
所有events的最小、最大、平均耗时
所有线程耗时总和
平均每线程完成events数/标准差
平均每线程耗时/标准差
来源:
https://blog.csdn.net/squirrel100/article/details/120289743
测试CPU
sysbench --time=60 --threads=4 --report-interval=3 --cpu-max-prime=10000 cpu run比如我这边的测试结果:
CPU speed:events per second: 13480.42Throughput:events/s (eps): 13480.4163time elapsed: 60.0013stotal number of events: 808843Latency (ms):min: 0.30avg: 0.30max: 0.5295th percentile: 0.30sum: 239646.46Threads fairness:events (avg/stddev): 202210.7500/49.35execution time (avg/stddev): 59.9116/0.01
测试内存
memory options:--memory-block-size=SIZE # 内存块大小 [1K]--memory-total-size=SIZE # 传输数据的总大小 [100G]--memory-scope=STRING # 内存访问范围 {global,local} [global]--memory-hugetlb[=on|off] # 从HugeTLB池中分配内存 [off]--memory-oper=STRING # 内存操作类型 {read, write, none} [write]--memory-access-mode=STRING # 内存访问模式 {seq,rnd} [seq]
测试内存
sysbench --threads=8 --time=60 --report-interval=10 --memory-block-size=8K --memory-total-size=4096G --memory-access-mode=seq memory run注意 total-size 一定要足够大才可以.
要是太小测试出来的结果可能比较失真.Total operations: 164485793 (2741367.30 per second)1285045.26 MiB transferred (21416.93 MiB/sec)Throughput:events/s (eps): 2741367.2990time elapsed: 60.0014stotal number of events: 164485793Latency (ms):min: 0.00avg: 0.00max: 0.2995th percentile: 0.00sum: 346268.33Threads fairness:events (avg/stddev): 20560724.1250/1260446.77execution time (avg/stddev): 43.2835/0.96
测试IO
# fileio options([]为默认参数):--file-num=N # 创建的文件数量 [128]--file-block-size=N # 在所有IO操作中使用的块大小 [16384]--file-total-size=SIZE # 要创建的文件的总大小 [2G]--file-test-mode=STRING # 测试模式 {seqwr(顺序写), seqrewr(顺序重写), seqrd(顺序读), rndrd(随机读), rndwr(随机写), rndrw(随机读写)}--file-io-mode=STRING # 文件操作模式 {sync(同步),async(异步),mmap} [sync]--file-extra-flags=[LIST,...] # 用于打开文件的附加标志列表 {sync,dsync,direct} []--file-fsync-freq=N # 执行N条请求数量后执行fsync() (0 - don't use fsync()) [100]--file-fsync-all[=on|off] # 每条写指令后执行fsync() [off]--file-fsync-end[=on|off] # 测试执行后执行fsync() [on]--file-fsync-mode=STRING # 同步方式 {fsync, fdatasync} [fsync]--file-merged-requests=N # 允许范围内,最多合并IO请求数量 (0 - don't merge) [0]--file-rw-ratio=N # 组合测试读/写比率 [1.5]
测试IO
# 线程数=8 每隔2s输出一次结果 测试时间=10s
# 文件数=32 文件总大小=1G 文件操作模式=随机读写
# 块大小 8KB
sysbench fileio --threads=8 --report-interval=2 --time=10 --file-num=32 --file-total-size=1G --file-test-mode=rndrw preparesysbench fileio --threads=8 --report-interval=2 --time=10 --file-num=32 --file-total-size=1G --file-test-mode=rndrw runsysbench fileio --threads=8 --report-interval=2 --time=10 --file-num=32 --file-total-size=1G --file-test-mode=rndrw prepare测试结果一般为:
Throughput:read: IOPS=8498.15 132.78 MiB/s (139.23 MB/s)write: IOPS=5665.43 88.52 MiB/s (92.82 MB/s)fsync: IOPS=4472.09Latency (ms):min: 0.00avg: 0.43max: 715.3495th percentile: 0.17sum: 80180.16
测试线程
--thread-yields=N number of yields to do per request [1000]--thread-locks=N number of locks per thread [8]
参数详解: --thread-yields=N 指定每个请求的压力,默认为1000--thread-locks=N 指定每个线程的锁数量,默认为8线程调度:线程并发执行,循环响应信号量花费的时间{越少越好}
测试线程调度器的性能。对于高负载情况下测试线程调度器的行为非常有用
测试线程
sysbench --threads=64 --report-interval=2 --time=10 threads run 注意 线程 64时的结果:
Throughput:events/s (eps): 3413.1149time elapsed: 10.0492stotal number of events: 34299Latency (ms):min: 0.65avg: 18.72max: 298.4795th percentile: 125.52sum: 642034.54Threads fairness:events (avg/stddev): 535.9219/56.01execution time (avg/stddev): 10.0318/0.01线程 1 时的结果
Throughput:events/s (eps): 1595.8521time elapsed: 10.0016stotal number of events: 15961Latency (ms):min: 0.61avg: 0.63max: 0.7595th percentile: 0.64sum: 9996.12Threads fairness:events (avg/stddev): 15961.0000/0.00execution time (avg/stddev): 9.9961/0.00鲜橙汁更加了 64倍 但是event才增加了一倍.
测试mutex
mutex options:--mutex-num=N total size of mutex array [4096]--mutex-locks=N number of mutex locks to do per thread [50000]--mutex-loops=N number of empty loops to do inside mutex lock [10000]参数详解:--mutex-num=N 数组互斥的总大小。默认是4096--mutex-locks=N 每个线程互斥锁的数量。默认是50000--mutex-loops=N 内部互斥锁的空循环数量。默认是10000互斥锁:并发线程同时申请互斥锁循环一定次数花费的时间{越少越好}
测试互斥锁的性能,方式是模拟所有线程在同一时刻并发运行,并都短暂请求互斥锁
![[openbve站]oldhelps openbve站v0.0.2推出上线公测](https://img2024.cnblogs.com/blog/2843980/202405/2843980-20240504135719845-1324522953.png)