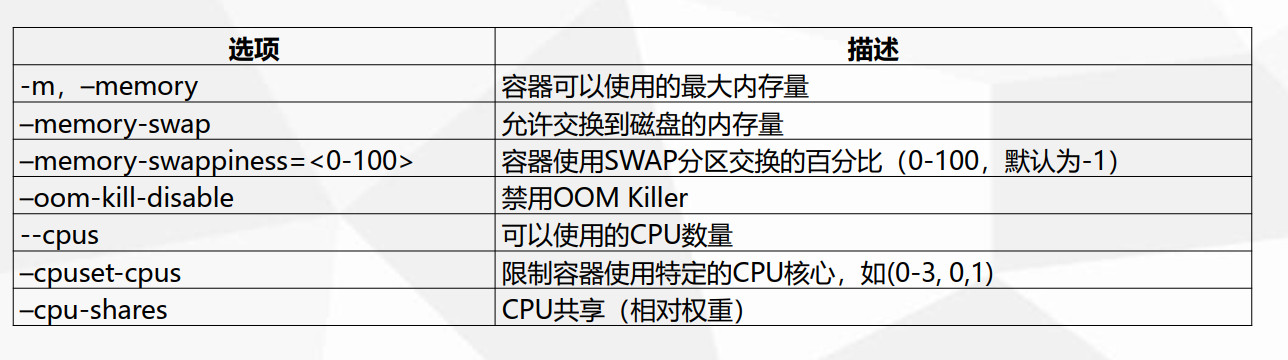
BERT问答
- BERT分为哪两种任务,各自的作用是什么;
- 在计算MLM预训练任务的损失函数的时候,参与计算的Tokens有哪些?是全部的15%的词汇还是15%词汇中真正被Mask的那些tokens?
- 在实现损失函数的时候,怎么确保没有被 Mask 的函数不参与到损失计算中去;
- BERT的三个Embedding为什么直接相加?
- BERT的优缺点分别是什么?
- 你知道有哪些针对BERT的缺点做优化的模型?
- BERT怎么用在生成模型中?
- BERT的两种任务:
- Masked Language Model (MLM):这个任务的作用是让模型学会理解文本中的上下文信息。在这个任务中,约15%的输入词汇会被随机遮蔽,然后模型需要预测这些被遮蔽的词汇。这帮助BERT学习词汇的双向上下文表示。
- Next Sentence Prediction (NSP):这个任务的作用是让模型理解文本之间的关系。模型会接受一对文本句子作为输入,然后判断这两个句子是否是连续的。这有助于BERT学习句子和文本段落之间的关系。
- MLM预训练任务的损失函数:
- 在计算MLM任务的损失函数时,只参与计算那些真正被Mask的tokens。BERT的输入序列中,大约15%的词汇会被随机选择并替换为[MASK]符号,模型需要预测这些位置上的词汇。只有这些被遮蔽的位置上的预测与真实标签进行比较,用于计算损失。其他位置上的词汇不参与计算损失。
- 确保未被Mask的tokens不参与损失计算:
- 在实现损失函数时,通常会使用掩码(masking)来确保未被Mask的tokens不参与损失计算。只有真正被Mask的位置上的预测与真实标签进行比较,其他位置上的损失被忽略。
- BERT的三个Embedding相加:
- BERT模型中包含三种嵌入(Embedding):Token Embedding、Segment Embedding和Position Embedding。这三种嵌入分别用于表示词汇、句子片段和词汇的位置信息。它们被相加在一起,以创建输入序列的最终表示。这种相加操作允许模型同时考虑词汇、句子关系和位置信息,有助于模型更好地理解文本的上下文。
- BERT的优缺点:
- 优点:
- 强大的上下文表示:BERT学会了深度的上下文表示,适用于多种自然语言处理任务。
- 预训练和微调:可以通过预训练模型在特定任务上微调,使其适应各种应用领域。
- 解决一词多义问题:通过上下文信息,能够更好地处理一词多义问题。
- 缺点:
- 预训练代价高昂:训练BERT等大型模型需要大量的数据和时间。
- BERT没有解码器部分,因此不能直接用于生成序列的任务,如机器翻译。
- 优点:
- BERT的改进模型:
- ALBERT使用了参数共享策略,规模更小,NSP任务改成了SOP任务
- RoBERTa只使用MLM任务,去掉了NSP任务,从原版静态掩码改为动态掩码,使用了更大规模的训练数据。
- BERT在生成模型中的应用:
- BERT本身不是生成模型,但可以与生成模型结合使用,以改善生成任务的性能。一种常见的方法是将BERT用作编码器,将其生成的上下文表示馈送到生成模型(如GPT-3)中,以帮助生成更准确的文本。这种结合可以用于文本生成、对话系统和自动摘要等任务。
BERT精读
BERT: Bidirectional Encoder Representations from Transformers,双向Transformer编码器,用来做预训练,针对一般的语言理解任务。
BERT没有decoder结构,和单向的GPT相比,机器翻译、文本摘要一类的生成性任务不太好做。
Abs
BERT与ELMo和GPT相关,利用无标记文本联合左右的上下文信息来预训练双向表示。
- BERT v.s. ELMo:ELMo基于RNN,BERT基于Transformer;BERT+额外输出层就可以应用到不同的下游任务,只需要微调最上层;而ELMo应用到下游任务要对架构做调整
- BERT v.s. GPT:都基于Transformer;GPT学习单向表示,由左侧做预测,BERT学习双向表示
Intro
预训练语言模型主要用于两类NLP任务:① 句子层面的任务 ② 词源层面的任务 (token-level)
预训练表示用于下游任务的策略:① 基于特征 (ELMo学到的表示作为新的特征输入) ② 基于微调 (GPT根据新的数据集调整模型权重)
单向语言模型存在局限性!⇒ BERT:双向语言模型 ① 每次随机mask一些tokens,预测被盖住的词(完形填空)②下一句预测(两个句子是否相邻)
Related
- 无监督基于特征 - ELMo
- 无监督基于微调 - GPT
- 在有标记数据上做迁移学习
Method
2 steps: ① pre-training ② fine-tuning
架构
多层双向Transformer的编码器
L - Transformer块的个数 H - 隐层大小 A - 多头自注意力机制里的head个数 A * 64 = H
$BERT_{BASE}$:110M参数 L = 12, H = 768, A = 12
$BERT_{LARGE}$:340M参数 L = 24, H = 1024, A = 16
参数计算部分可以去复习Transformer精读的编码器架构

输入/输出表示
输入:一个句子/一个句子对,作为一个sequence输入,用WordPiece来切词
[CLS][句子A][SEP][句子B]
CLS学习整个序列的信息
每个token在嵌入层的输出(进入BERT的输入)由本身的embedding+属于哪个句子的embedding+ 位置embedding组成,每个embedding都是学习得到的

预训练
-
Masked LM (MLM) : WordPiece生成的每个token(即不包括CLS和SEP)有15%可能性被mask
❗微调的时候不用mask,导致了预训练和微调的mismatch
解决方法:15%被mask的词源里,80%的可能真的被[MASK],10%的可能被替换为随机token,10%的可能不变(模拟微调的场景)


-
Next Sentence Prediction (NSP) : 判断句子对<A, B>是否相邻(50% IsNext,50%NotNext)


微调
根据特定的下游任务设计输入/输出,BERT+输出层经过softmax得到label

- Case 1:情感分析

用预训练参数初始化BERT比随机初始化更快更好!

- Case 2:词性标注

- Case 3:立场分析


- Case 4:基于文本提取的QA



实验
任务集benchmark:General Language Understanding Evaluation (GLUE)
在9个任务上取正确率均值,评估自监督学习模型的好坏
拓展
-
预训练sequence-to-sequence模型
编码器输入被破坏的序列,解码器重建输入

破坏的方式多样:mask单字、删除、置换、旋转、填词

-
BERT是怎么工作的?
Case 1:
和CBOW很像,结合了上下文的深度word embedding


推测:BERT学到了上下文相关的语义,同义字学到的embedding比较近
Case 2:
但BERT不仅能学到语义,没有含义的句子也能拿来做分类任务!(如DNA分类)

推测:BERT的能力不完全来自于能看懂文章,还可能有其他理由。(或许本质上就是比较好的初始化参数!)
Case 3:
用104种语言预训练的Multi-lingual BERT,用英文QA微调,在中文QA上做测试,效果竟然不错!

推测:BERT能学到跨语言的同义字对齐(深 - deep)实验证明对齐需要大量训练数据!
Case 4:
如果不管什么语言,同义字的embedding都很近,重建时语言为什么不会乱掉?

推测:BERT还可以学到不同语言之间的差异!
把所有中文embedding的均值和英文embedding的均值做差值,英语输入通过Multi-BERT得到的输出加上这个差值做重建,或许能得到相近的中文词!

实验发现,真的可行!!

非常有趣的结果!
我的个人想法:不同的语种或许可以视为不同的domain,加上均值差异的过程或许可以视为特征对齐,实际上是在做域适应(Domain Adaptation)!
那么机器翻译可不可以当成DA来做?
有空准备实验一下自己的想法,但大概率已经有前辈做过了吧!
-
模型压缩
BERT是一个很大的模型,有没有办法让它变小呢?
因此出现了Distill BERT、Tiny BERT、Mobile BERT、Q8BERT、ALBERT…

放一个链接:
All The Ways You Can Compress BERT
-
Adaptor
BERT是个大模型,对每一个下游任务都做微调,多个下游任务要存储大量参数!

因此引入Adapter,微调时只调整Adaptor的参数,多个下游任务可以共享model参数!

下图为Adaptor的位置及其架构:

-
特征加权
每一层抽取出来的信息会不一样,不同的下游任务可能会关注不同层的信息,哪个层的信息比较重要(权值)让下游任务自己来学习

-
UniLM
既可以做Encoder,也可以做Decoder,也可以作为Encoder+Decoder+ ELECTRA


-
ELECTRA
对于每个token的输出都做二元分类:yes/no,预测当前token是否被替换
比预测mask的词更简单,同时每个位置的输出都能用上
如果是意思相差很大的词,则学到的无意义(对机器来说太简单!)
怎么生成意思差不多但又不一样的词呢?用small BERT来生成被mask的词!

注意:这不是GAN!small BERT自己训练,不需要骗过分类器