框架图与动机结构化与可重定目标代码生成
用于数值计算的代码生成方法传统上侧重于优化循环嵌套的性能。相关分析侧重于标量元素,因为循环嵌套的主体通常计算单个元素。这样的分析必须考虑内存依赖性与混叠。这些方法在过去进行了深入研究,并已达到高度成熟。当从像C或Fortran这样的输入语言开始时,它们非常适合,其中问题已经根据存储在预分配内存中的数据上的循环来指定。
当关注一个特定的领域(例如ML空间)时,可以在比循环高得多的抽象级别上定义程序。这为重新审视经典的循环优化(如融合、平铺或向量化)提供了机会,而无需复杂的分析与启发式。优点包括降低了复杂性与维护成本,同时还可以自然扩展到稀疏张量等扩展,这些扩展甚至更难在循环级别进行分析。
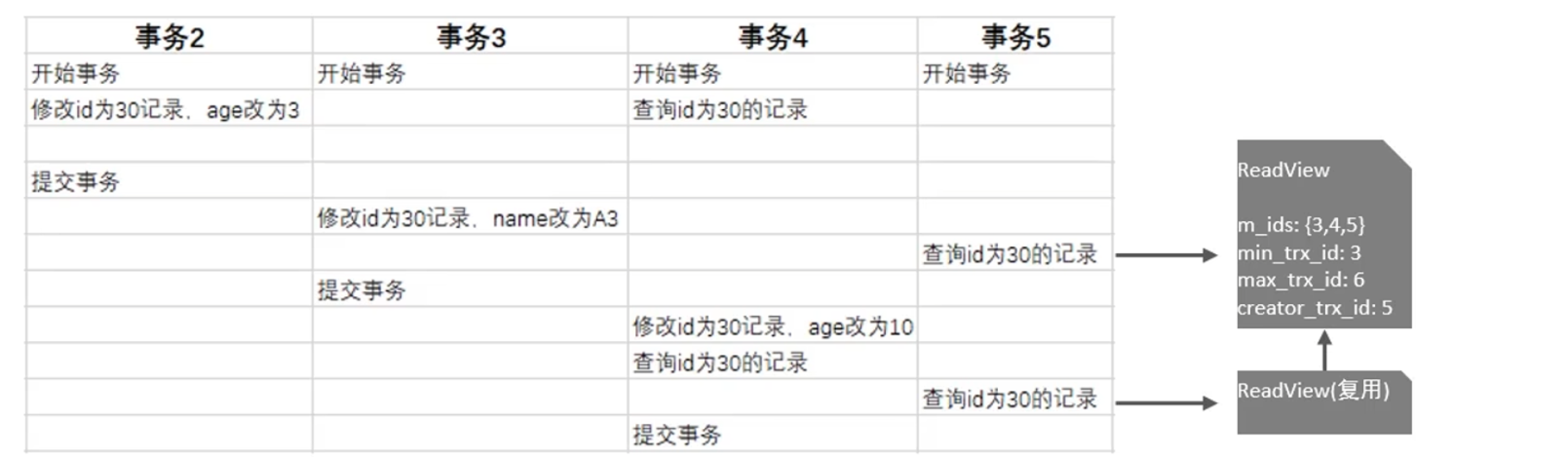
可以避免在可行的情况下通过静态分析从较低级别的表示中提取信息,并在尽可能高的抽象级别执行优化。将这种方法称为结构化代码生成,因为编译器主要利用源代码中现成的结构信息。如图8-1所示,展示了所涉及的步骤与抽象级别的粗粒度摘要结构。
起点(结构化IR)由张量代数运算组成,作为稠密与稀疏张量上的函数程序组织。
图8-1 结构化与可重构目标代码生成的框架图
从这个级别转到平铺结构级别,它通过平铺操作引入循环。多个渐进的平铺步骤是可能的,并且不一定会导致标量周围的循环。相反,平铺会在类似于原始操作但在较小张量上的结构化操作周围产生循环。还在这个级别上执行张量运算的融合。选择操作的最终粒度是为了使其硬件映射高效。一个典型的例子是将矩阵乘法平铺以对缓存层次结构进行建模,然后将较小的矩阵乘法直接下译到汇编语言中的超优化微内核。
将生成的小张量的计算映射到(可重定目标的)向量抽象。这种映射利用了精心保存的有关操作的高级知识。不需要分析包含精细训练张量运算的环路控制流。这一步骤还可能包括启用诸如填充之类的转换,以实现高效的缓存访问,而不需要缓存行拆分与向量化。
结构化代码生成具有高度可组合性与可重用性,是因为平铺与融合转换在操作与数据类型中都是完全通用的。这些转换仅假设与计算与合成数据相关的通用、单调(从集合包含的角度来看)的结构分解模式。密集张量代数与稀疏张量代数都表现出这种分块分解模式,代码生成抽象与基础设施通常适用于这两者。
MLIR中的可组合与模块化代码生成,通用格式的MLIR定义,代码如下:
//第8章/value_definition.c
%value_definition = "dialect.operation"(%value_use) {attribute_name = #attr_kind<"value">} ({
// Regions contain blocks.
^block(%block_argument: !argument_type):
"dialect.further_operation"()[^successor]: () -> ()
^successor:
// 以下更多操作
}): (!operand_type) -> !result_type<"may_be_parameterized">
MLIR具有一组开放的属性、操作与类型。
可以将表示直接转换为MLIR的LLVM方言,以便在CPU上顺序执行,或者卸载GPU内核,或者将循环拆分为异步块,用于任务并行运行时等。
该流程由现有的仿射分析与MLIR中实现的环路优化组成的。
2.2 与代码生成相关的方言
设计与实现的特定于领域的抽象包括以下方言的表示,这些方言在不断提高的抽象级别中列出。遵循模块化与可选性设计原则,如果这些方言不能为特定情况提供有用的抽象,则可以与其他方言混合,或者简单地绕过。
2.3.1向量方言。这种方言提供了固定秩的n-D向量类型,例如向量<4×3×8×f32>,以及形成直观且可重定目标的向量编程模型的操作,该模型在概念上将传统的1-D向量指令扩展到任意秩。这样的操作可以逐渐分解为其自身的较低级别的变体。当后端启发式足够健壮以生成接近峰值的组装或绕过该级别并直接针对硬件特定的内部(例如gpu.subgroup_mma_compute_matrix 2-D向量指令或amx.tile_mulf 2-D网格指令)时,它们进一步下译到LLVM向量指令(例如shufflevector)。
2.3.2 gpu方言。gpu方言定义了可重定目标的gpu编程模型。它的特点是SIMT平台通用的抽象,如主机/设备代码分离、工作项/组(线程/块)执行模型、通信与同步原语等。这种方言可以从向量方言中产生,并且本身可以下译到特定于平台的方言,如nvvm、rocdl或spirv。它只是为了说明方法的总体可重定目标性而列出的,没有进一步讨论。
2.3.3 memref方言。memref方言引入了memref数据类型,它是MLIR中n-D内存缓存的主要表示,也是基于内存的副作用操作的接口,以及管理缓存分配、混叠(memref视图)与访问的操作。与传统指针不同,memrefs是具有显式布局的多维缓存,允许将索引方案与底层存储解耦:memref<10×10×f32,steps:[1,10]>提供列主访问,同时具有行主存储。memref数据类型还提供了一个与外部C代码互操作的ABI,这对于与库交互非常有用。
2.3.4张量方言。张量方言对抽象的n-D张量类型进行运算,尚未决定其在内存中的表示。在编译过程中,静态大小的足够小的张量可以直接放置在(向量)寄存器中,而较大或动态大小的张量由于缓存处理而被放入存储器中。张量值是不可变的,并且受定义的约束。使用SSA语义,对张量的操作通常没有副作用。这允许经典的编译器转换,如视觉优化、常量子表达式与死代码消除,或循环不变代码运动,无缝地应用于张量运算,而不管其潜在的复杂性如何。由于张量值是不可变的,因此无法将其写入。相反,值插入操作会创建替换了值或其子集的新张量。
2.3.5 scf方言。结构化控制流scf方言提供表示循环与条件的操作(例如,没有提前退出的常规scf.fo与scf.while循环以及scf.if条件构造),并将它们嵌入MLIR的SSA+区域形式中。这是在比控制流图更高的抽象层次上构建的,scf循环操作可以产生SSA值。
2.3.6. linalg方言。linalg方言提供了更高级别的计算原语,可以在张量与memref容器上操作。
2.3.7. 稀疏张量方言。稀疏张量方言提供了使稀疏张量类型成为MLIR编译器基础结构中的类型与转换,将高级线性化与低级操作桥接,以节省内存并避免执行冗余工作。
2.4. 下层方言:生成LLVM IR与二进制
MLIR编译器流的简单可视化描述,如图8-2所示。
图8-2 MLIR编译器流的简单可视化描述:(顶部)仅限LLVM方言,(底部)LLVM与x86向量方言,后者包含硬件特定的内在操作。
图8-2(顶部)总结了工具流程。在转换过程的最后,MLIR生成多个编译路径所共有的低级方言。LLVM方言与LLVM IR非常相似,使用这种方言的MLIR模块,可以在移交给LLVM编译器以生成机器代码之前被翻译成LLVM IR。这种方言重用内置的MLIR类型,如整数(i32)或浮点(f32)标量。
MLIR提供了一些低级别的特定于平台的方言:nvvm、rocdl、x86vector、arm_neon、arm_sve、amx等。这些方言部分镜像了LLVM IR内部函数的相应集合,这些函数本身通常映射到硬件指令。除了使这些指令成为一流的操作与提供之外,这些方言还定义了使用MLIR的可扩展类型系统与其他功能的稍高级的操作。例如,
arm_neon.2 d. sdot: vector <4 ×4× i8 >, vector <4 ×4× i8 > to vector <4×i32 >
运算自然地表达在MLIR多维向量类型上。在转换为LLVM IR之前,它首先被下译到
arm_neon. intr. sdot: vector <16×i8 >, vector <16×i8 > to vector <4×i32 >
其对平铺的1-D向量进行操作以匹配LLVM的约定。
3. 转换
考虑到linalg.cov_1d_nwc_wcf操作及其下译为平铺、填充与向量化形式,在转换IR时逐步遵循IR,如图8-3所示。输入IR如图8-3(左)所示。
图8-3 张量上的卷积平铺引入了具有二次诱导变量(伪IR)的循环。为了清晰起见,斜体部分被简化,并在标注中扩展。欠核心部分指的是新概念:(左)对不可变张量的运算,(右)二次诱导变量与张量切片。
这种抽象级对不可变的SSA值进行操作:从现有的张量值创建新的张量值。在随后的下译步骤中,内存位置仅作为函数边界处的注释出现,以指定这些张量将如何具体化到内存中。
对应于linalg.cov_1d_nwc_wcf的索引表示法,由在三维张量上操作的5-D矩形迭代域以及表达式给出:

迭代域隐含在操作描述中,并且迭代器跨越操作数的整个数据。这是由不等式给出的

其中

表示的大小𝑑-的第个维度

。这些量的推导遵循与张量理解相同的规则。在稠密情况下,可以通过傅立叶-莫兹金消去过程导出。
3.1平铺
拼接操作引入了scf.for循环,以及子集操作(tensor.extract_slice与tensor.insert_slice)来访问拼接数据,如图4(右)所示。操作的平铺形式本身就是对平铺子集进行操作的linalg.cov_1d_nwc_wcf。稠密子集的推导是通过每个张量的索引函数计算迭代域的图像来获得的。
选择了1×8×32×1×8的网格尺寸。虽然这些尺寸是静态的,但有些划分不是整体的,边界网格需要进行完整/部分网格分类。因此,不存在对每个循环迭代有效的单一静态张量类型;平铺张量类型!tDyn必须松弛到一个动态成形的张量。访问网格数据切片所需的动态网格大小为%8、%9与%11。
这种张量平铺变换引入的scf.for循环执行循环嵌套,每次迭代时产生的全张量值的迭代收益。每个tensor.insert_slice与scf.yield都会产生新的值,缓存过程有责任避免多余的分配与拷贝。
3.2填充值与包装
应用平铺时,平铺的内容通常会变得更加动态,以考虑边界效果。这阻碍了需要静态大小的向量化。有多种缓解方案:
1)平铺可能会触发多级循环剥离(或版本控制),以在主循环中隔离问题的静态已知常量部分,然后清除边界循环。
清理循环仍然表现出动态行为,但它们总是可以按1平铺,并进一步减少到大小为1的维度,该维度可以以更细粒度的形式进行向量化。
2)一种替代方案是将动态网格填充到更大的已知静态尺寸。用于填充的值必须是消耗操作的中性值。
3)第三种选择是转向包含显式掩模的表示。
为了简洁起见,斜体部分被简化。罗马字体中的常量是属性,斜体是arith.constant运算结果。
nofold填充即使在没有类型改变的情况下也会在IR中持续存在,并且可以放置在快速缓存器中。尾部类型注释有时为了简洁而省略。当计算不需要足够的时间局部性时,剥离几乎总是更好的选择。一旦某个时间位置可用,填充所需的副本就可以摊销。一旦发生缓存,填充还用于对齐填充缓存中的内存访问。
如图8-4所示,示例中输入张量填充由3个循环提升。这引入了一个特定的网格循环嵌套来预计算填充网格,并将它们插入到类型为tensor<?的压缩张量中?x?x1x8x8xf32>包含所有填充网格。在原始网格循环嵌套中,填充被对压缩tensor%12=tensor.extract_slice%PI的访问所取代。
图8-4 填充平铺操作以获得固定大小的张量(高亮显示),pseudo-IR。
3.3向量化
如图8-5所示,在平铺与填充之后,卷积操作数是静态成形的,并且处于良好的向量化状态,见图8-5(左)。在当前的IR中,只有两种类型的操作需要向量化:tensor.pad与linalg.cov1d_nwc_wcf。
tensor.pad的向量化是用一个简单的一次性模式实现的,该模式将其简化为一对vector.transfer_read与vector.ttransfer_write操作。有了这样的运算,tensor.pad的向量化相对来说是一个非常小且渐进的下译步骤。
图8-5(右)显示了操作vector.control正在运行。
直线运算的向量化遵循引入向量的配方。对于每个操作数transfer_read,以向量形式执行计算,并通过vector.transfer_write将其提交回适当的张量或缓存。vector.transfer操作按照linalg操作的索引表达式进行索引。
每个线性运算都有一个表示计算的标量形式的体区域。体向量化取决于linalg.generic执行的索引类型:
图8-5对固定大小张量的运算可以直接向量化,伪IR。
为了简洁起见,斜体部分被简化,如图8-5所示。向量值是不可变的。它们可以从张量中读取与写入张量。
允许越界访问;读取复制标量操作数,写入被忽略。
1) 在点操作的最简单情况下(索引都是恒等式),主体中的每个操作都简单地写成点向量变体;
2) 较低维度的张量操作数可以是向量,将其转换为较高维度的向量;
3) 索引表达式中的置换是用vector.transpose操作处理的;
4) 缩小尺寸低于一级向量,多重缩小取决于对实体的进一步分析;
5) 通过沿着某些维度展开并提取进一步缩减为vector.control或vector.fma的切片,可以特别处理诸如卷积之类的滑动窗口模式。这种简单的策略在捕捉跳跃与扩张卷积中提供了高性能。
在图8-5(右)的运行示例中,将展开与%kw循环相对应的尺寸。使用了不会进一步展开的网格尺寸1。注意%16 = vector.extract %15[0]:!vecK运算,其是大小为1的展开切片提取的退化形式。出现了特定的规范化与折叠模式,简化了vector.transfer操作链,并将独立于循环的指令移出循环(例如,%8 = vector.transfer_read)。循环loops %9 = scf与%12 = scf,两者都在不插入张量或从张量中提取的情况下产生向量值,这将保证缓存后不会往返内存。所有这些转换都是通过遵循SSA定义实现的。
3.4缓存
缓存是将张量值具体化到内存(memref)中的过程。有必要使张量程序通过存储在内存中的数据源具体可执行。在当前的编译管道中,这是最后一步。
MLIR中的张量是不可变的。产生新张量值的运算(可能来自另一个输入张量)在概念上是一个全新的张量。与memrefs不同,这里没有更新/写入张量的概念。为了获得良好的性能,必须:
1)分配尽可能少的内存;
2)复制尽可能少的内存。
缓存应尽可能重复使用并更新到位,否则当程序转换导致意外分配与复制时,可能会带来巨大的性能损失,如图8-6所示。
图8-6 左侧:输出张量参数,与操作的结果绑定,采用目的地传递样式。右边:一个读后写冲突的例子。
写入后读取冲突。为每次内存写入分配一个新的缓存总是安全的,但会浪费内存并引入不必要的副本。另一方面,如果必须在稍后读取重写的内存位置上的原始数据,则重用缓存并将其写入到位可能会导致无效的缓存化。在执行转换时,必须小心地保留依赖关系的程序语义。图8-6的右侧显示了一个潜在的写后读取(RaW)冲突,该冲突阻止了本地缓存。高效缓存的问题与寄存器合并有关,寄存器合并是与消除寄存器到寄存器移动相关的寄存器分配子任务。
目的地传递风格。目前提供的用于缓存的启发式算法,非常适合目的地传递方式的操作。在这样的操作中,其中一个张量自变量与生成的张量绑定,用于原位缓存。这样的张量自变量被称为输出张量,见图8-6的左侧。输出张量类似于C++输出参数,这些参数作为非常量引用传递并返回计算结果。除了输出张量(自变量)与运算结果用作缓存约束,对函数语义没有可观察的影响;输出张量看起来仍然是不可变的。在缓存期间,当寻找将运算结果写入的缓存时,只考虑输出张量。
当用scf.fo(下译多维张量运算的自然目标)构成结构化运算时,其原理来源于第一性原理。由于scf.fo因此产生一个值,因此其嵌套区域必须产生完全定义的张量,而不是任意子集。由于嵌套运算通常应用于张量子集——通常是由线性平铺变换产生的——因此通常会注入一对匹配的extract_slice/insert_slice运算。这些相关的scf.yield操作自然会消耗张量自变量(即,不能有任何后续使用),这使它们成为就地缓存的理想候选者,如图8-7所示所示。
这种启发式设计似乎对在使用linalg方言时处理的IR类型很有效:
1)平铺产生了在平铺子集上迭代的外循环。管理这些子集的操作,如extract_slice、insert_slice,自然是目的地传递样式。
2)填充、打包、向量化与其他转换,也会在全张量或子集上产生具有目的地传递风格语义的操作。
3)linalg.generic本身被设计为目的地通行式操作。这包括linalg.matmul与任何其他简化为linalg.generic的操作。
图8-7 Bufferization将张量值分配给缓存,同时考虑图8-3中的函数级注释#in与#out。数据流被副作用所取代,不必要的值在左边被划掉。可以分配临时缓存器以确保连续的访问模式。计算有效载荷方言,如linalg与vector,旨在支持张量与memref(缓存)容器。
可以将tensor.insert作为目标Pass风格的操作示例。运算的张量结果在缓存化框架中可能有一个或多个潜在的混叠运算操作数。例如,示例中%0的唯一潜在混叠运算操作数是%A(图8-6,左侧),这意味着缓存化后:
1)buffer(%0) = buffer(%A)
2)或者:buffer(%0)是新分配的缓存。
选择缓存时不考虑其他操作数。对于张量结果没有潜在混叠操作数的运算,总是分配一个新的缓存。例如,tensor.generate总是在缓存后进行分配。
3.5向LLVM逐步下译多维向量运算
此时,IR已经达到了由包含多维向量的缓存周围的循环与对这些向量的操作组成的抽象级别。这现在接近LLVM的C++向量范式,只是对多维向量进行操作,而LLVM只有一维向量。
在最简单的情况下,多维vector.transfer操作低于多个一维vector.load与vector.store操作。当硬件支持时,它们也可以下译到n-D DMA操作。在更复杂的情况下,传输操作下译到广播、传输与屏蔽散射/聚集的组合。在不能确定向量转移在边界内的特定情况下,必须在完全转移与部分转移之间采用特定的分离,类似于网格级别的完全与部分网格分离,如图8-8所示。这在linalg.copy(%21,%22)操作周围的else块中,如图8-8(右)所示。
对n-D向量类型的广泛使用有效地屏蔽了一种展开与阻塞的向量形式,这种形式在向量硬件上是有效的,不受可能干扰后期向量化的中间编译阶段的影响。在这一点上,这种形式已经准备好逐步下译到一维操作,几乎1-1映射到LLVM IR。
图8-8 向量方言可以逐步下译到对一维向量进行更简单的运算。图示为下译对外部产品的收缩,为简洁起见,斜体部分简化,重复部分省略。较低级别的向量运算需要恒定的索引,并且是通过展开外部维度来生成的。
如图8-9所示,从左侧的向量化矩阵乘积代码开始。该IR(主要)是可重定目标的,因为它使用的是通常与可用硬件指令不对应的更高级别的传输与合同操作。首先应用向量展开,如图8-9(a)所示。这种转换的目标有两个:
1)将向量运算分解为已知的目标很好支持的大小,例如映射到AMX指令;;
2)将2个大小的非幂运算优先处理为2个组合的幂运算,例如,将向量<12×f32>处理为3个向量<4×f32>,以避免次优后端代码生成。所得到的IR仍然是部分可重定目标的,因为转移与契约操作仍然存在,并且需要使用可用方案之一将其下译到更接近硬件的表示。
vector.extract_strided_slice与vector.insert_rided_stice将向量的切片提取并插入到更大的向量中。如果目标形状匹配,折叠图案可能导致插入与提取操作相互抵消。
更高级别的vector.transfer_read通常不能直接下译到加载指令,而是逐步处理:首先,如图10(b)所示,通过物化换位;然后,如图8-9 (c)所示,创建1-D加载与广播。根据配置的不同,转置可以通过LLVM的shuffle指令或使用专用的内部函数来实现。
vector.control可以下译到外积、内(点)积或LLVM IR矩阵内部。在图8-9(d)中被下译到外积,以实现到图8-9(e)中SIMD融合的乘加指令的进一步映射。逐步下译的每个阶段都伴随着折叠与视觉优化,这些优化减少了要处理的IR量,并实现了特定的转换。因此,完全下译的向量IR在向量<8×f32>上运行,例如由AVX2支持,并且非常紧凑。示例的结果代码有几十个操作,这些操作已准备好下译到LLVM方言,并进一步转换为LLVM IR。
图8-9 表示矩阵乘积的向量方言运算的渐进式下译:(a)目标形状为2×8×2的向量展开引入了向量切片操作;(b) 转移置换被具体化为转置运算;(c) 一维传递变为具有形状适应性的平面载荷;(d) 收缩重写为外积(其他选项也是可能的),这反过来又下译到(e)融合的乘加指令。
4. 单线程CPU实验
机器学习内核上评估代码生成框架。所有基准测试都测量单线程CPU性能,并与机器的峰值性能进行比较。
4.1前言:驾驶实验
MLIR为Python提供了一组绑定,支持通用的IR创建与操作。基础设施旨在促进多级元编程,并推动了这些绑定的设计。还提供了一种嵌入Python中的自定义域特定语言(DSL),称为OpDSL。OpDSL的目的是将API范式从构建编译器IR转变为以简洁、人性化与数学上令人信服的形式表达计算,这在张量理解方面取得了成功。OpDSL中的一种多态矩阵乘法,代码如下:
//第8章/ linalg_matmul.py
@linalg_structured_op
def matmul(A=tensorDef(T1, S.M, S.K), B=tensorDef(T2, S.K, S.N), C=tensorDef(T3, S.M, S.N, output=True)):
C[D.m, D.n] += cast(T3, A[D.m, D.k]) * cast(T3, B[D.k, D.n])
该流程利用并扩展了用于JIT编译与执行的最小MLIR执行引擎。流处理的结构化数据对象在Python中开放为与Python缓存协议兼容的对象。因此,它们可以转换为NumPy数组,也可以从NumPy阵列转换,后者可以进一步转换为特定于框架的数据类型。
此外,在Python中提供了一个测试与基准测试工具,以自动测量编译与运行时以及GFLOP等性能数据/𝑠 用于计算与GB/𝑠 用于内存流量。该工具还使用多种转换策略来封装编译与执行,代码如下:
//第8章/Tiling_Expert.py
# 编译专家可以通过将转换类彼此链接或与专家链接来定义
SingleTilingExpert = Tile.then(Generalize).then(Vectorize).then(Bufferize).then(LowerVectors).then(LowerToLLVM)
DoubleTilingExpert = Tile.then(SingleTilingExpert)
TripleTilingExpert = Tile.then(DoubleTilingExpert)
# 编译专家可以通过其所包含的转换的选项的融合来参数化
concrete_double_tiling = DoubleTilingExpert(
sizes1=[32, 32], sizes2=[8, 4], pad2=True, vectorize_padding=True, contraction_下译='outer')