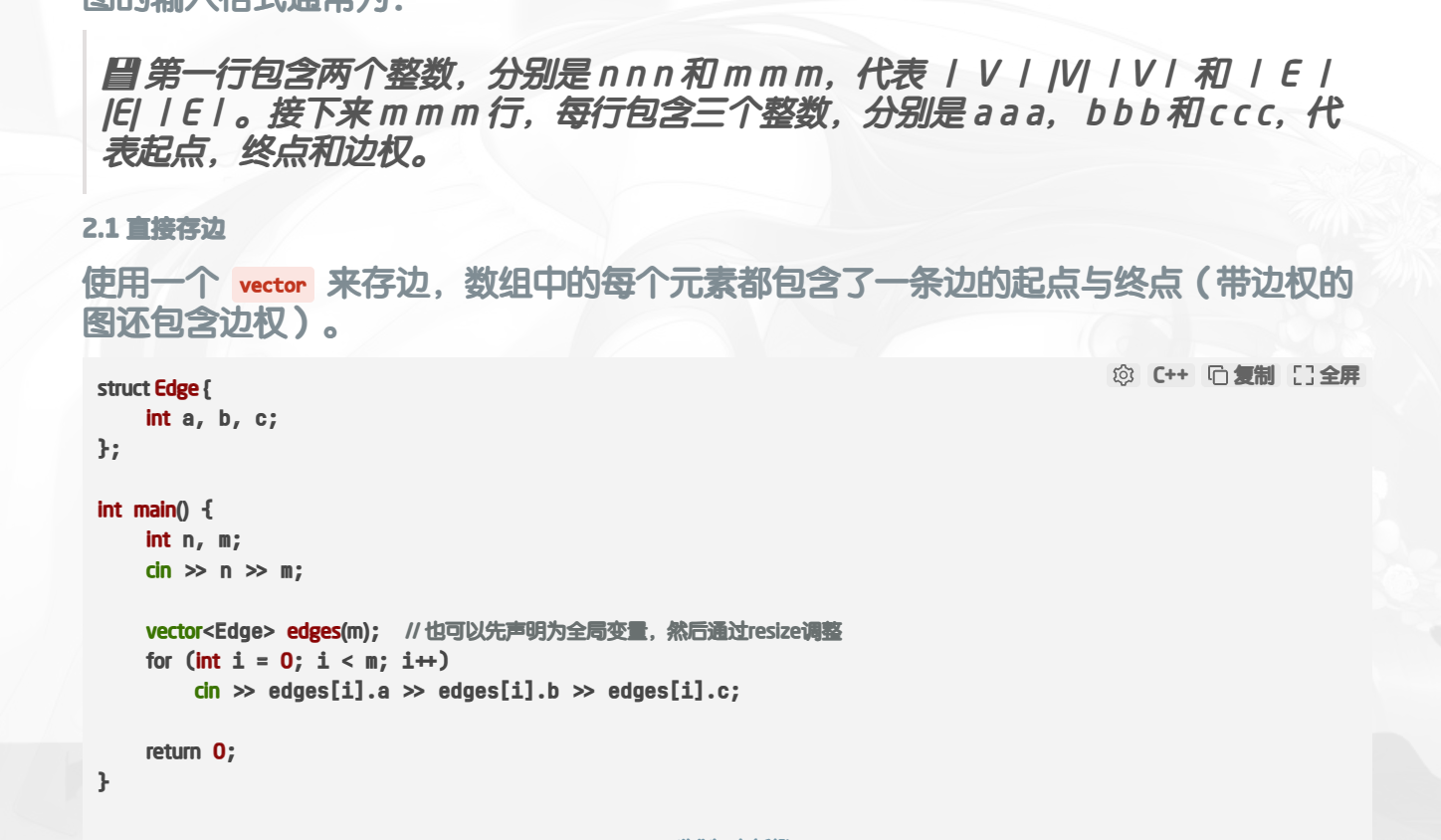
老古董(低效,不建议用):
原理是所有操作都加同步块
// Vector
Vector<String> vector = new Vector<String>();// Hashtable
Hashtable<Integer, String> hashtable = new Hashtable<Integer, String>();
老古董2.0版(换汤不换药):
原理还是所有操作都加同步块
List:Collections.synchronizedList
Set:Collections.synchronizedSet
Map:Collections.synchronizedMap
这三个使用方式完全一致,以下只演示List:
// 创建一个线程不安全的ArrayList
List<String> list = new ArrayList<>();
// 将ArrayList转换为线程安全的List
List<String> synchronizedList = Collections.synchronizedList(list);// 在同步块中操作List
synchronized (synchronizedList) {synchronizedList.add("元素1");synchronizedList.add("元素2");synchronizedList.add("元素3");
}// 同步块内读取List
synchronized (synchronizedList) {for (String element : synchronizedList) {System.out.println(element);}
}
高效3.0:
// 原理:写时复制,每次修改操作先复制出一份新数组,在新数组上做修改,完成后把指针指向新数组。
// 修改操作加互斥锁,读操作无锁
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();// 底层使用了CopyOnWriteArrayList,Put操作调用了:addIfAbsent()保证元素不重复。
CopyOnWriteArraySet<String> set = new CopyOnWriteArraySet<>();// 基于跳表(Skip List)数据结构实现,由于不需要写时复制,写入效率比ArraySet高,读取效率比ArraySet低。
ConcurrentSkipListSet<Integer> set = new ConcurrentSkipListSet<>();// ConcurrentHashMap 使用分段锁(Segment Locking)或者锁分离技术来减少锁的竞争,从而提高并发性能。
// 在 JDK 1.8 之前,ConcurrentHashMap 由多个 Segment 组成,每个 Segment 包含一个小的 HashMap,锁是针对Segment的。
// 从 JDK 1.8 开始,ConcurrentHashMap 使用了 CAS 操作和 synchronized 来实现并发控制,不再使用分段锁。
ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();